

白话空间统计二十四:地理加权回归(六)ArcGIS的GWR工具参数说明一
(再次接近6000字,诚意满满啊)
从这一章开始进入实际操作环节……首先还是用ArcGIS,毕竟这个东西比较容易。
实际上要说起来,GWR有专门的软件,叫做GWR,但是这个软件暂时我还没有用过,所以等我先学习一下,把他放到最后才说了,先用比较熟悉的,比如ArcGIS、比如R语言,这些来讲讲(还有一个我非常熟悉的软件是GEODA,可惜GEODA仅支持回归分析,不支持地理加权回归)。
数据还是用上次山东的那一份,在番外篇中,用财政收入作为因变量,自变量选择工业总产值,消费品零售额,总出口以及固定资产投资作为自变量,完成了OLS回归分析,然后进行了残差可视化,有兴趣的同学去翻翻以前的文章:
白话空间统计二十三回归分析番外:残差可视化
看看要进行分析的数据: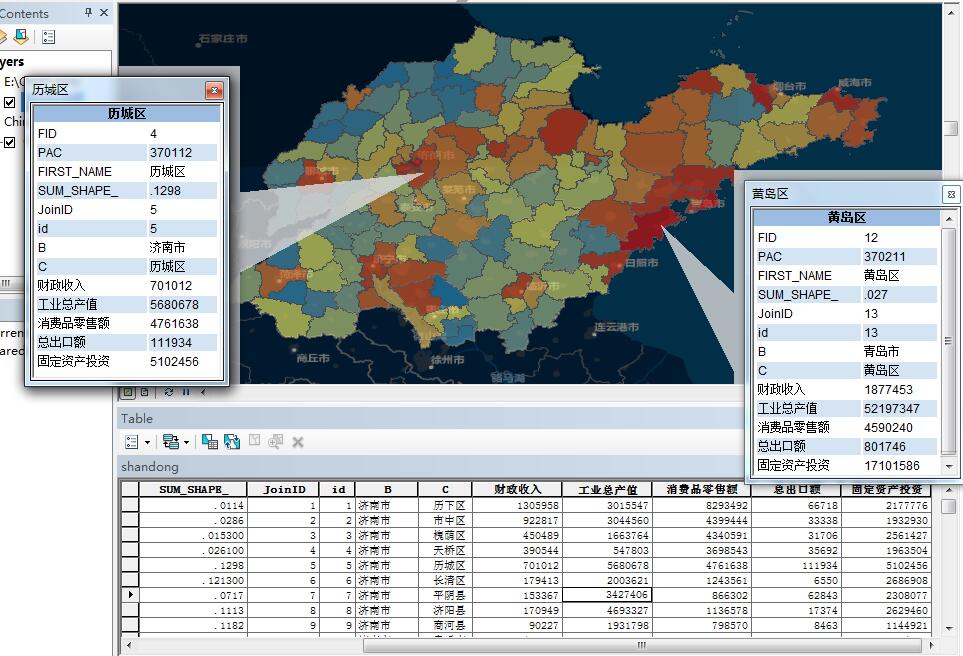

下面先来解释一下ArcGIS提供给我们的GWR工具的各个参数设置:
地理加权回归分析工具的位置,在空间统计工具箱——空间关系建模工具集——地理加权回归工具(如下所示:)

下面是各个参数的意义(话说这一部分在ArcGIS帮助文档里面都有的,但是我知道要让大家像虾神这样(变态)无聊,把ArcGIS帮助文档放到手机上,还是有点勉为其难,所以这这里写了)

虾神私人推介……有兴趣做空间统计的,可以把ArcGIS的帮助文档拷贝到手机上……很多APP都直接直接打开chm格式的。
工具界面如下:
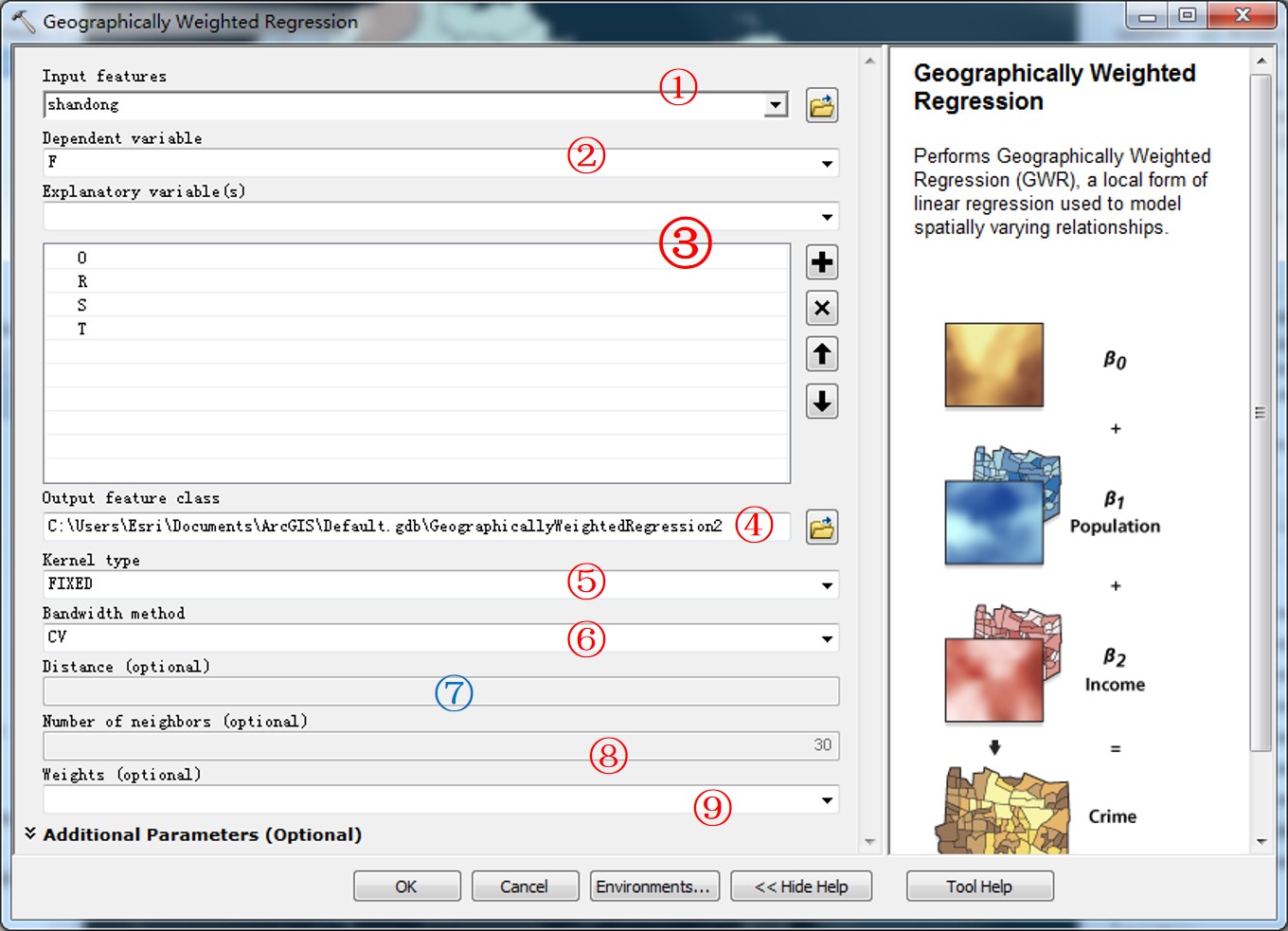

1、输入要素:
ArcGIS的空间统计工具箱,主要针对的是矢量数据,所以这里的输入一定是矢量图层,可以是点线面,但是不能是多点(但是可以是多部分要素,因为对面状空间要素处理的时候,通常采用的是质心来进行计算,多部分面状要素不会影响GWR的处理)。
在要素类的设定上,应该避免有空间错误的数据:比如有属性无空间要素,如果出现这样的数据,可能会发生错误。
在制作数据的时候,尽量把需要使用的数据都合并到一个要素类中,每一个变量(应、自)都应该是一列独立的数据,而且一定不能出现空值(如果出现了空值,或者表示空值的0值,首先就要将这行数据从分析样本中移除,或者补全之后在使用。
使用的变量中,尽量不要使用哑元(dummy,ArcGIS的官方翻译中,把这个词翻译成“哑元”,实际上在实际上在计量经济学里面,把它称为:虚拟变量(dummy variable),意思是表示该变量只能表示“有”和“无”这两种情况,在计算机里面常备称为二值化变量,即放到模型中就只有1和0两个值,比如该时间发生了,就记为1,没发生就记为0。在计量经济学里面,dummy variable是很重要的一个概念,大家有兴趣自己去查询相关资料,这里为了保持上下文一致,我使用ArcGIS的翻译方法,把这个东东继续叫做“哑元”)
因为在使用二值化的时候,到底哪个类别为0,那个类别为1,是可以任意设置的(比如前进和后退,可以认为前进设置为1,后退设置为0,也可以反向设置,后退为1,前进为0)不管如何设置,都不会影响检验的结果。在GWR中,如果使用哑元作为某个变量的值,会导致分析中出现严重的多重共线性。
空间统计分析里面,空间关系概念一旦涉及“距离”的时候,尽量使用投影坐标系,当然,如果使用经纬度,对分析的过程不会产生多大影响,但是对分析的结果会有一些影响(特别是对核带宽进行设置的时候)。
(关于输入要素的其他情况,有兴趣的时候专门开一篇数据处理来讲……这里先直接略过了)
2、因变量字段。
这个字段包含因变量的值,一个回归方程只能有一个因变量,没啥好说的。注意别使用哑元就好了。
3、解释变量(自变量)字段。
包含了解释变量的字段,最少一个。系统会自动筛选掉文本型的数据,只保留数值型。但是不筛选哑元值,所以需要自行设置。
另外,自变量的顺序和分析的结果没有任何关系。
4、输出结果
用户承载分析结果的要素图层,分析结果的解读后面会详细说。
5、核的类型
此参数并非是让我们选择核函数(ArcGIS只提供了高斯核函数,没得选),这参数是让我们决定核函数如何构成?分析的数据用什么方式来参与。 工具提供两种核函数:
FIXED :固定距离法,也就是按照一定的距离来选择带宽,创建核表面
ADAPTIVE :自适应法。按照要素样本分布的疏密,来创建核表面,如果要素分布紧密,则核表面覆盖的范围小,反之则大。
默认会使用固定方式,因为固定方式能够生成更加平滑的核表面。
6、核带宽
此参数用于设定GWR的带宽,通过以前的文章,我们知道带宽的选择非常关键,而且GWR专门用两种方式来选择更好的带宽,但是也留出了自定义的模式,所以这个参数有三个选项:
CV:通过交叉验证法来决定最佳带宽。
AIC:通过最小信息准则来决定最佳带宽。
BANDWIDTH_PARAMETER :指定宽度或者临近要素数目的方法。如果选择这种方法,后面的7\8两个参数,才变为可用状态。如果选择CV或者AIC法,带宽是通过计算来决定的,所以距离参数将不可用。而采用指定的方法,我们可以通过自定义的方式,来决定带宽
为什么需要留出这样一个可以自定义带宽的参数呢?因为CV法和AIC法,都是系统计算出来的带宽,特别是AIC法,可能能够达到很好的拟合度,但是回归是不是拟合度越高越好呢?这就不一定了,特别很多时候选择不同的带宽,可以揭示更多的细节的时候。
关于这个问题,可以参考下面的文章:
白话空间统计二十一:密度分析(五)
7、距离(可选)
如果在参数6中,选择了自定义带宽模式,那么这个参数就变为可用了。注意,这里设定的带宽距离单位,是要素类的空间参考中的单位,如果你是经纬度的话,这里设定的也是经纬度(设置为1,就是1度,在中国范围内,约为108公里左右),所以如果要更精确,最好把数据投影为投影坐标系。
8、临近要素的数目(可选)
如果核类型为自适应(ADAPTIVE),以及核带宽为BANDWIDTH_PARAMETER的时候,此参数才为可用,默认是30,表示选择回归点周边的30个点作为核局部带宽中作为临近要素的点。
9:权重字段(可选):
本工具可以对每个要素设置独立的权重,把这个将要设定的权重写入一个字段,然后设置到此就行。
一旦设置了权重,就说明这个(些)要素在进行校验的时候,会比其他要素更加重要。
在很多时候,独立设置的权重有着很重大的意义。如下图所示:
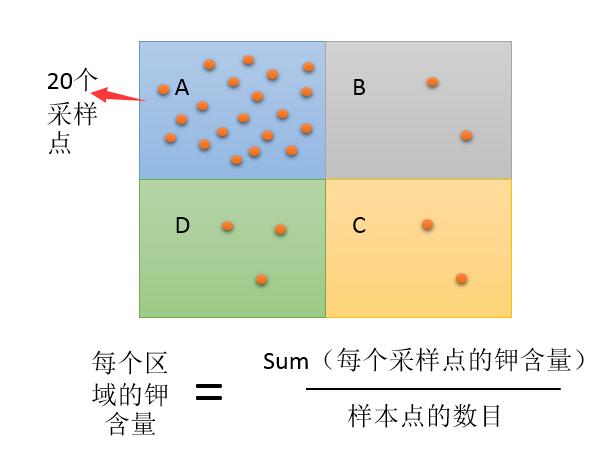
要用4个区域的钾含量要进行计算,那么就从四个区域布点进行采样,用采样的平均值来作为每个区域的含量值,可以看见A区域足足布置了20个采样点,D区域3个,BC分别都是2个,这样来说,A区域的钾含量是20个点的平均值,在四个区域里面,A区域的钾含量最接近平稳值,所以在计算的时候,我们可以把每个区域的采样点数放到一个字段里面,作为这个区域的权重——这样来说,在计算的时候A区域的数据,比其他几个区域的数据具有更大的影响力。

具体的参数就先说到这里,GWR后面还有一系列的扩展参数,下一节我们再继续说。
待续未完。
转载自:https://blog.csdn.net/allenlu2008/article/details/69935417









