

Python Scripting for ArcGIS
目录
学习资源: 《面向ArcGIS的Python脚本编程》
英文版更详细 Python Scripting for ArcGIS
练习数据和资源 Esri官方资源
书一共分为四部分,第一部分是Python和地理处理的相关概念(第一章到第四章),第二部分是编写地理处理脚本(第五章到第九章),第三部分是执行地理处理任务(第十章到第十二章),最后一部分是 创建并使用脚本工具(十三到十四章)。核心主要是第二部分。
Part 2 Writing Scripts
Chapter 5 Geoprocessing using Python
引用工具函数的两种方法(推荐第一种)


跳过可选参数的三种方法


设置工作空间和环境
>>> from arcpy import env
>>> env.workspace = "C:/EsriPress/Python/Data/Exercise05">>> env.overwriteOutput = True
>>> env.outputCoordinateSystem = spatial_ref坐标系类(SpatialReference类)
需要实例化之后使用
>>> prjFile = "C:/EsriPress/Python/Data/Exercise05/facilities.prj"
>>> spatial_ref = arcpy.SpatialReference(prjFile)
>>> arcpy.DefineProjection_management("hospitals", spatial_ref)
The result is <Result 'hospitals'>.>>> print spatial_ref.name
The result is
NAD_1983_StatePlane_Texas_Central_FIPS_4203_Feet显示工具的提示信息
arcpy.Clip_analysis("parks.shp", "zip.shp", "Results/parks_Clip.shp")
print arcpy.GetMessages()
# 输出所有的提示信息
msgCount = arcpy.GetMessageCount()
print arcpy.GetMessage(msgCount-1)
# 输出指定的提示信息Chapter 6 Exploring spatial data
使用工具前判断文件是否存在(arcpy.exists)
python自带的函数os.path.exist函数主要是判断文件是否存在,也就是必须要写出完整文件的后缀名,而Arcpy中的exists函数则是可以对不同类别的要素进行判断是否存在。
import arcpy
from arcpy import env
env.workspace = "C:/EsriPress/Python/Data/Exercise06"
if arcpy.Exists("cities.shp"):
arcpy.CopyFeatures_management("cities.shp", "results/cities_copy.shp")判断数据类型(Describe)
type = arcpy.Describe("cities.shp").shapeType
if type == "Polygon":
# 需要使用的函数
else:
print "The feature are not polygons"
数据库中的数据类型非常重要,因为数据库中的户数据元素没有文件扩展名。
文件地理数据库后缀名 .gdb
个人地理数据库后缀名.mdb
企业地理数据库后缀名.sde
>>>import arcpy
>>>element = "C:/Data/study.gdb/final"
>>>desc = arcpy.Describe(element)
>>> arcpy.Describe(element).datasetType
u'FeatureClass'
>>> arcpy.Describe(element).ShapeType
u'Point'
Describe函数返回一个具有很多属性的Describe对象,包含文件路径、目录、路径、文件名称等属性。
>>> mylayer = arcpy.Describe("cities")
>>> mylayer.dataType
#Running the code returns u'FeatureLayer'.
>>> mylayer.shapeType
The result is u'Point'.
----------
>>> mylayer.spatialReference.name
The result is u'GCS_North_American_1983'.
>>> mylayer.spatialReference.type
The result is u'Geographic'.
>>> mylayer.spatialReference.domain
The result is u'-400 -400 400 400'.列表批处理
import arcpy
from arcpy import env
env.workspace = "C:/Data"
# 列出目录下所有文件名
fclist = arcpy.ListFeatureClasses( )
print fclist
# [u'floodzone.shp', u'roads.shp', u'streams.shp', u'wetlands.shp', u'zipcodes.shp']
# 列出以w开头的文件名
fclist = arcpy.ListFeatureClasses( "w*" )
# 列出点要素
fclist = arcpy.ListFeatureClasses( "", "point" )
# 列出栅格数据
rasterlist = arcpy.ListRasters( "", "tif" )
import arcpy
from arcpy import env
env.workspace = "D:/Archive01/03Coding/ArcGIS+Python/EsriPress/Python/Data/Exercise06"
fc_list = arcpy.ListFeatureClasses()
for fc in fc_list:
desc = arcpy.Describe(fc)
print desc.basename + "is a " + desc.shapeType +"feature class."
#另外一种 print "{0} is a {1} feature class".format(desc.basename, desc.shapeType)列表元组和字典
元组不可修改,元组为(),列表为[],字典{},引用是均用[]
cities = ["Austin", "Baltimore", "Cleveland", "Denver"]
states = ["Texas", "Maryland", "Ohio", "Colorado"]
>>> states[cities.index( "Cleveland" )]或者直接用字典查询
>>> statelookup = {"Austin": "Texas", "Baltimore": "Maryland", "Cleveland": "Ohio", "Denver": "Colorado"}
>>> statelookup["Cleveland"]
>>> statelookup.key()
>>> statelookup.values()
# 以列表的形式返回
>>> zoning.items( )
The result is [( 'IND', 'Industrial' ), ( 'RES', 'Residential' )].Chapter 7 Manipulating spatial data(Arcpy.da)
游标实际上就是类似SQL的一种查询功能,或者说条件筛选。通过游标搜索得到的记录会输出到一个字段列表中。
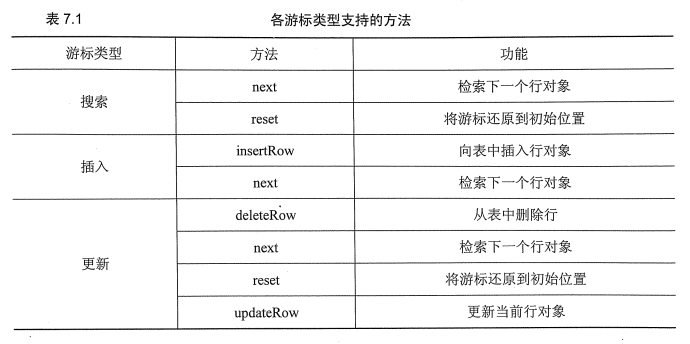

- SearchCursor 搜索游标检索行
- InsertCursor 插入行
- UpdateCursor 更新和删除行
搜索游标
import arcpy
from arcpy import env
env.workspace = "D:/Archive01/03Coding/ArcGIS+Python/EsriPress/Python/Data/Exercise07"
fc = "airports.shp"
cursor = arcpy.da.SearchCursor(fc,["NAME"])
for row in cursor:
print "Airport name = {0}".format(row[0])
del row
del cursor
# Airport name = New Stuyahok
# Airport name = Ted Stevens Anchorage International
# Airport name = Iliamna
# Airport name = Koyukuk- 使用with,无论游标成功运行还是出现异常,都可以保证数据库锁的关闭和释放,并重新迭代
import arcpy
fc = "C:/Data/study.gdb/roads"
with arcpy.da.SearchCursor( fc, ["STREETNAME"] ) as cursor:
for row in cursor:
print "Streetname = {0}".format( row[0] )- SQL语句中,字段格式有(“”)([]),AddFieldDelimiters函数
cursor = arcpy.da.SearchCursor(fc, ["NAME"], '"TOT_ENP" > 100000')
cursor = arcpy.da.SearchCursor(fc,["NAME"],'"NAME" = \'Ketchikan\'')
cursor = arcpy.da.SearchCursor(fc, ["NAME"], '"FEATURE" = \'Seaplane Base\'')
# 注意此时对于条件的书写,不同的文件由不同的格式
delimitedField = arcpy.AddFieldDelimiters(fc, "COUNTY")
cursor = arcpy.da.SearchCursor(fc, ["NAME"], delimitedField + " = 'Anchorage Borough'")
插入游标
import arcpy
from arcpy import env
env.workspace = "C:/EsriPress/Python/Data/Exercise07"
fc = "Results/airportsCopy.shp"
cursor = arcpy.da.InsertCursor(fc, "NAME")
cursor.insertRow(["New Airport"])
del cursor更新游标
import arcpy
from arcpy import env
env.workspace = "C:/EsriPress/Python/Data/Exercise07"
fc = "Results/airports.shp"
delimfield = arcpy.AddFieldDelimiters(fc, "STATE")
cursor = arcpy.da.UpdateCursor(fc, ["STATE"], delimfield + " <> 'AK'")
for row in cursor:
row[0] = "AK"
cursor.updateRow(row)
del row
del cursor
# 删除
fc = "Results/airports.shp"
cursor = arcpy.da.UpdateCursor(fc, ["TOT_ENP"])
for row in cursor:
if row[0] < 100000:
cursor.deleteRow()
del row
del cursor表和字段
- ValidateTableName( name, {workspace} )将无效字符替换为下划线(_)
# 将shp文件转移到地理数据库
import arcpy
import os
from arcpy import env
env.workspace = "C:/Data"
outworkspace = "C:/Data/test/study.gdb"
fclist = arcpy.ListFeatureClasses( )
for shapefile in fclist:
fcname = arcpy.Describe( shapefile ).basename
newfcname = arcpy.ValidateTableName( fcname )
outfc = os.path.join( outworkspace, newfcname )
arcpy.CopyFeatures_management( shapefile, outfc)- 新增字段检测
import arcpy
from arcpy import env
env.workspace = "C:/EsriPress/Python/Data/Exercise07"
fc = "Results/airports.shp"
newfield = "NEW CODE"
fieldtype = "TEXT"
fieldname = arcpy.ValidateFieldName(newfield)
fieldlist = arcpy.ListFields(fc)
fieldnames = []
for field in fieldlist:
fieldnames.append(field.name)
if fieldname not in fieldnames:
arcpy.AddField_management(fc, fieldname, fieldtype, "", "", 12)
print "New field has been added."
else:
print "Field name already exists."
处理文本文件
f = open("D:/Archive01/03Coding/ArcGIS+Python/mytext.txt")
f.read()#读取全部
f.seek(0)
f.read(5)
f.readline()
f.readlines()#以列表的形式返回所有的行
f.close()
# 写入行
f= open("D:/Archive01/03Coding/ArcGIS+Python/mytext.txt","r+")
f.write("Triangulated\nIrregular\nNode" )
f.read()
f.close()
# 修改指定行
f= open("D:/Archive01/03Coding/ArcGIS+Python/mytext.txt","r+")
lines = f.readlines()
lines[2] = "Network"
f.writelines(lines)
# 遍历行
f = open( "C:/Data/mytext.txt" )
for line in f.readlines( ):
<function>
f.close( )Chapter 8 Working with geometries(处理几何图形)
几何对象的属性
– SHAPE@XY will return a tuple of x,y coordinates representing the feature’s centroid
– SHAPE@LENGTH will return the feature’s length as a double
– SHAPE@ will return the full geometry object
读取几何
import arcpy
from arcpy import env
env.workspace = "D:/Archive01/03Coding/ArcGIS+Python/EsriPress/Python/Data/Exercise08"
# 求周长
fc = "rivers.shp"
cursor = arcpy.da.SearchCursor(fc, ["SHAPE@LENGTH"])
length = 0
for row in cursor:
length = length + row[0]
units = arcpy.Describe(fc).spatialReference.linearUnitName
print str(length) + " " + units
# 输出XY坐标
fc = "dams.shp"
cursor = arcpy.da.SearchCursor(fc, ["SHAPE@XY"])
for row in cursor:
x, y = row[0]
print("{0}, {1}".format(x, y))读取线和面(single part)
- 线和多边形,访问其中的每一个要素都会返回一个点对象组。想要处理这些数组,需要两次迭代,第一个for循环遍历行对象(即一条线和多边形记录),需要输入OID(对象标识符)字段,用来指明每一个点对象数组的起始位置和结束位置。访问每一个行对象都会获得一个几何对象,该对象是一个点对象数组。getPart函数可以用来获取几何图形的第一部分的点对象数组。第二个for循环用来遍历每一个线或多边形中的点,并输出x、y坐标值。
fc = "rivers.shp"
cursor = arcpy.da.SearchCursor(fc, (["OID@", "SHAPE@"]))
for row in cursor:
print("Feature {0}: ".format(row[0]))
for point in row[1].getPart(0):
print("{0}, {1}".format(point.X, point.Y))
- 注意到getPart()函数索引值为零,只返回几何对象的第一部分,对于singlepart要素类只有第一部分。如果没有索引值,则会返回一个包含所有点对象数组的数组。
多要素(点线面)
- 多个要素只有一个字段表,
# 判断要素类用shapeType属性,Point, Polyline, Polygon, MultiPoint, and MultiPatch(三维数据)几种返回值。
fc = "Hawaii.shp"
print arcpy.Describe(fc).shapeType
# 判断属性
fc = "Hawaii.shp"
cursor = arcpy.da.SearchCursor(fc, ["OID@", "SHAPE@"])
for row in cursor:
if row[1].isMultipart:
print("Feature {0} is multipart and has {1} parts.".format(row[0],str(row[1].partCount)))
else:
print("Feature {0} is single part.".format(row[0]))- 多边形要素类的xy点
cursor = arcpy.da.SearchCursor(fc, ["OID@", "SHAPE@"])
for row in cursor:
print("Feature {0}: ".format(row[0]))
partnum = 0
for part in row[1]:
print("Part {0}: ".format(partnum))
for point in part:
print("{0}, {1}".format(point.X, point.Y))
partnum += 1内环


写入几何图形
- 创建线文件
# Write geometries
import fileinput
import string
import os
env.overwriteOutput = True
outpath = "D:/Archive01/03Coding/ArcGIS+Python/EsriPress/Python/Data/Exercise08"
newfc = "Results/newpolyline.shp"
# 创建几何图形
arcpy.CreateFeatureclass_management(outpath, newfc, "Polyline")
# 坐标点文件
infile = "D:/Archive01/03Coding/ArcGIS+Python/EsriPress/Python/Data/Exercise08/coordinates.txt"
#
cursor = arcpy.da.InsertCursor(newfc, ["SHAPE@"])
array = arcpy.Array()
# 第一种创建线文件
# 将文档中的内容分到ID,X,Y三个字段。
for line in fileinput.input(infile):
ID, X, Y = string.split(line," ")
array.add(arcpy.Point(X, Y))
# 插入到新文件中
cursor.insertRow([arcpy.Polyline(array)])
fileinput.close()
del cursor
# 第二种创建面文件
point = arcpy.Point( )
for line in fileinput.input( infile ):
point.ID, point.X, point.Y = line.split( )
array.add(point)
polygon = arcpy.Polygon(array)
cursor.insertRow([polygon])
fileinput.close()
del cursor
challenge
- 通过坐标点创建
fc = "newpoly2.shp"
arcpy.CreateFeatureclass_management("C:/Data", fc, "Polygon")
cursor = arcpy.da.InsertCursor(fc, ["SHAPE@"])
array = arcpy.Array()
coordlist =[[0, 0], [0, 1000], [1000, 1000], [1000, 0]]
for x, y in coordlist:
point = arcpy.Point(x,y)
array.append(point)
polygon = arcpy.Polygon(array)
cursor.insertRow([polygon])
del cursor- 统计每个singlepart的周长和面积
fc = "Hawaii.shp"
newfc = "Results/Hawaii_single.shp"
arcpy.MultipartToSinglepart_management(fc, newfc)
spatialref = arcpy.Describe(newfc).spatialReference
unit = spatialref.linearUnitName
cursor = arcpy.da.SearchCursor(newfc, ["SHAPE@"])
for row in cursor:
print ("{0} {1}".format(row[0].length, unit))
print ("{0} square {1}".format(row[0].area, unit))- 创建最大长方形包围圈
fc = "Hawaii.shp"
newfc = "envelope8.shp"
desc = arcpy.Describe(fc)
spatialref = desc.spatialReference
extent = desc.extent
arcpy.CreateFeatureclass_management("D:/Archive01/03Coding/ArcGIS+Python/EsriPress/Python/Data/Exercise08", newfc, "Polygon", "", "", "", spatialref)
cursor = arcpy.da.InsertCursor(newfc, ["SHAPE@"])
array = arcpy.Array()
array.append(extent.upperLeft)
array.append(extent.upperRight)
array.append(extent.lowerRight)
array.append(extent.lowerLeft)
polygon = arcpy.Polygon(array)
cursor.insertRow([polygon])
del cursorChapter 9 Working with rasters(处理栅格图形 Arcpy.sa)
ListRasters
rasterlist = arcpy.ListRasters("*","IMG")
for raster in rasterlist:
print raster栅格数据基本特征


raster = "tm.img"
desc = arcpy.Describe(raster)
print "Raster base name is: " + desc.basename
print "Raster data type is: " + desc.dataType
print "Raster file extension is: " + desc.extension
print "Raster spatial reference is: " + desc.spatialReference.name
print "Raster format is: " + desc.format
print "Raster compression type is: " + desc.compressionType
print "Raster number of bands is: " + str(desc.bandCount)
print "Raster meanCellHeight is: " + desc.meanCellHeight
print "Raster meanCellWidth is: " + desc.meanCellWidth
# 输出栅格图层的基本属性处理栅格对象
# 引入栅格数据,之后进行计算
elevraster = arcpy.Raster("elevation")
outraster3 = elevraster * 3.281
outraster3.save("elev_ft")
# 使用工具
outraster = arcpy.sa.Slope("elevation")
outraster2 = arcpy.sa.Aspect("elevation")
outraster.save("Aspect")
# 多图层计算
elev = arcpy.Raster("elevation")
lc = arcpy.Raster("landcover.tif")
slope = Slope(elev)
aspect = Aspect(elev)
goodslope = ((slope > 5) & (slope < 20))
goodaspect = ((aspect > 150) & (aspect < 270))
goodland = ((lc == 41) | (lc == 42) | (lc ==43))
outraster = (goodslope & goodaspect & goodland)
outraster.save("C:/EsriPress/Python/Data/Exercise09/Results/final")转载自:https://blog.csdn.net/leeloo666/article/details/72539364







