ArcGIS教程:大型数据集的分块处理
为改善要素叠加工具(如联合和相交)的性能和可伸缩性,软件采用了称为自适应细分处理的运算逻辑。当可用的物理内存不足以对数据进行处理时,就会触发系统使用此逻辑。由于保持在物理内存的可用范围内可以极大地提高性能,因此基于对原始范围的细节上,处理可逐步进行。跨越多个子块(也称为分块)边缘的要素会在分块的边缘处被分割开,并会在处理过程的最后阶段重新组合为一个要素。这些分块边缘处所引入的折点仍会保留在输出要素中。如果正在处理的要素过大,以至于细分处理无法使用可用内存将此要素恢复成原始状态,则分块边界也会保留在输出要素类中。
为何要细分数据?
当计算机的物理内存(或 RAM)够用时,叠加分析工具可以获得最佳性能。但是,当处理包含大量要素的数据集或包含数十万或数百万个折点的极复杂要素的数据集时,情况就不乐观了。如果不使用分块方法,物理内存耗尽后会使用虚拟内存,而虚拟内存耗尽后将使用内部分页系统。后续的每个内存管理模式(物理、虚拟、内存分页),其速度较前一模式都会呈指数递减。
分块是什么样的?
每次处理都是从覆盖整个数据范围的单个分块开始。如果单个分块中的数据过大而无法在物理内存中进行处理,则会将其细分成四个等大的分块。然后,再对子分块进行处理。如果第二级分块中的数据仍然过大,则会再进一步细分。此过程将持续执行,直到可以在物理内存中处理每个分块的数据为止。请参见以下示例:


所有输入要素的轮廓线
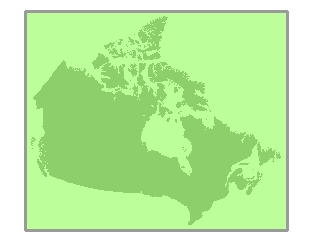
将从覆盖整个数据集范围的分块开始进行处理。为方便叙述,我们将此分块称为 1 级分块。
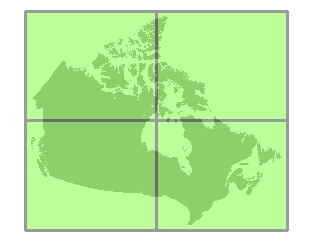
如果数据过大而无法在内存中进行处理,则 1 级分块将被细分成四个等大的分块。这四个子分块被称为 2 级分块。
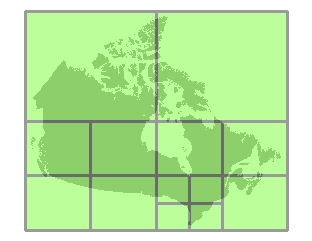
根据各分块中数据的大小,某些分块会被进一步细分,而另一些则不会。
哪些工具采用细分逻辑
“分析工具”工具箱中的以下工具在处理大型数据时会采用细分逻辑:
- 缓冲(使用融合选项时)
- 裁剪
- 擦除
- 标识
- 相交
- 分割
- 交集取反
- 联合
- 更新
“数据管理”工具箱中的以下工具在处理大型数据集时也会采用细分逻辑:
- 融合
- 要素转线
- 要素转面
- 面转线
处理过程因内存不足而失败
当处理超大型要素(包含数百万个折点的要素)时,细分方法可能也无能为力。沿分块边界多次分割和重新组合超大型要素的内存开销相当巨大。如果要素过大,则会导致出现内存不足的错误。这取决于运行此进程的计算机上的可用物理内存或 RAM 的大小。一些较大的要素在一台计算机配置上会产生内存不足的错误,而在另一台计算机配置上却不会出现错误。在同一台计算机上,内存不足的错误也可能会时而发生时而不发生,这取决于其他应用程序所占用的资源。举例来说,整个城市的道路轮廓或表示复杂河口的多边形,就属于具有大量折点的超大要素。
如果某个工具正在进行处理时又运行了另一个应用程序或地理处理工具,也会出现内存不足的错误。第二个进程会占用一部分细分进程认为应该可以使用的物理内存,从而导致细分进程所需要的物理内存大于实际可用的物理内存。因此,建议您在处理大型数据集时不要在计算机上执行其他操作。
建议在处理之前使用切分工具将较大的要素分割成较小的要素。
处理大型数据时建议使用哪种数据格式?
个人地理数据库和 shapefile 的大小被限制在 2 千兆字节 (GB)。如果进程的输出超过 2 GB,就会出现错误。由于企业地理数据库和文件地理数据库没有大小限制,因此在处理超大型数据集时建议使用这两种地理数据库作为输出工作空间。有关企业地理数据库的数据加载策略的详细信息,请联系数据库管理员。请勿执行未经计划/未获批准的大型数据加载操作。
转载自:https://blog.csdn.net/dsac1/article/details/50634125