

(十二)arcpy开发&利用arcpy实现在arcgis中对要素数据某一个字段值分类分割shapefile数据输出
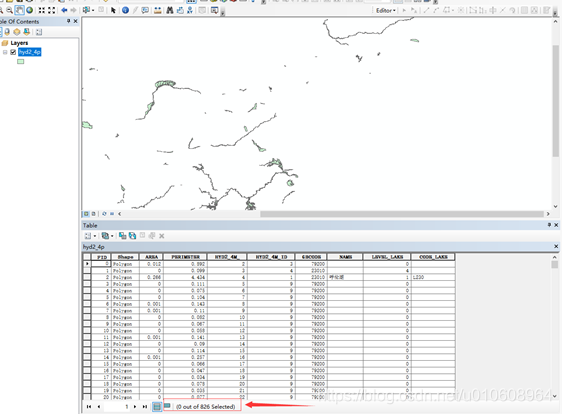
今天我们要学习这个功能是利用arcpy在arcgis实现对某一个要素属性数据shapefile的某一字段进行数据的筛选。实现的过程使用了SelectLayerByAttribute_management函数将该字段中的某一个字段值分出来,然后将数据另存为shapefile文件。我们来看一下这里的测试功能,我们对如下图的数据操作,从中可以看出属性记录一共有800多条,现在对FID字段进行分类选择,那么最后选出来的数据应该是826条,因为每一条数据都是为一个的,即每一个新创建的shapefile数据都是唯一条(FID是唯一的)。

来看一下实现的代码,注意使用SelectLayerByAttribute_management函数必须要创建临时图层,我们这里使用了MakeFeatureLayer_management函数,该函数在设置第二参数时要起到一个别名,我们这里起了”layer”,如果不起名字,当然也可以不设置,使用none。如果使用临时图层“layer”,那么在CopyFeatures_management、SelectLayerByAttribute_management也可以使用到。具体实现看一下源代码。
#coding=utf-8
import arcpy
import os
import re
import sys
import traceback
def build_where_clause(table, field, value):
field_delimiters = arcpy.AddFieldDelimiters(table, field)
field_type = arcpy.ListFields(table, field)[0].type
if str(field_type) == "String":
value = "'{}'".format(value)
where_clause = "{} = {}".format(field_delimiters, value)
return where_clause
def func(features,field_name,workspace):
try:
arcpy.env.workspace = r"in_memory"
arcpy.env.scratchWorkspace = r"in_memory"
arcpy.env.overwriteOutput = True
#features_layer = arcpy.MakeFeatureLayer_management(features, "layer")
features_layer = arcpy.MakeFeatureLayer_management(features, None)
with arcpy.da.SearchCursor(features, field_name) as cursor:
field_set = set()
for row in cursor:
field_value = str(row[0])
if field_value in field_set:
continue
else:
field_set.add(field_value)
sql_exp = build_where_clause(features, field_name, field_value)
arcpy.SelectLayerByAttribute_management(features_layer, "NEW_SELECTION", sql_exp)
#arcpy.SelectLayerByAttribute_management("layer", "NEW_SELECTION", sql_exp)
field_value = re.sub("[^\w]+", "", field_value)
output_file = os.path.join(workspace, field_value[:15])
arcpy.CopyFeatures_management(features_layer, output_file)
#arcpy.CopyFeatures_management("layer", output_file)
arcpy.AddMessage("Created file: " + output_file)
except:
tb = sys.exc_info()[2]
tbinfo = traceback.format_tb(tb)[0]
pymsg = ('PYTHON ERRORS:\nTraceback info:\n' + tbinfo + '\nError Info: \n'
+ str(sys.exc_info()[1]))
msgs = 'ArcPy ERRORS:\n' + arcpy.GetMessage(2) + '\n'
arcpy.AddError(msgs)
print pymsg
finally:
arcpy.Delete_management('in_memory')
features="D:\Data\中国国界和省界的SHP格式数据\三级以上河流\hyd2_4p.shp"
field_name="FID"
workspace="D:\Data\中国国界和省界的SHP格式数据\esult"
func(features,field_name,workspace)
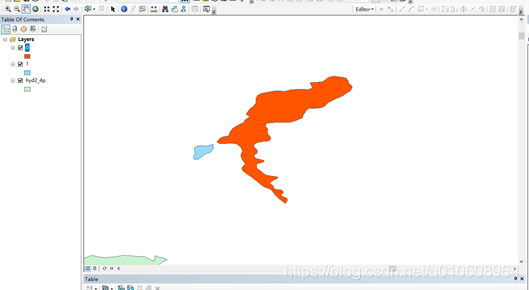
最后的分类结果如下图所示。


我们将0.shp、1.shp数据来到Arcgis Desktop来看一下分类结果,其中分别对应了蓝色和橙色数据。

更多内容,请关注公众号


转载自:https://blog.csdn.net/u010608964/article/details/87022499





