

利用geopandas包对PostGIS数据库插入地理空间数据及性能对比
最近在使用Python中的geopandas包操作地理空间数据,由于数据量过大采用PostgreSQL中的PostGIS进行管理操作,最后查到了一些资料代码插入数据库,国内网上没有相关内容,这里分享一下,自己以后也需要对大批量数据操作,这里对比下不同数据量下的插入性能。
环境:
- 笔记本windows7 64位(内存8G) Python 3.5.2(Anaconda3)
- PostgreSQL 10 PostGIS 2.4.2
- geopandas 0.3.0 sqlalchemy 1.2.2 GeoAlchemy2 0.4.2
基本流程是生成n个随机的空间散点,然后对比下不同n取值下的插入效率,所有的代码如下:
import pandas as pd
import geopandas as gpd
import time,datetime
import numpy as np
import shapely
from geoalchemy2 import Geometry, WKTElement
from sqlalchemy import *
start = time.clock()
print(str(datetime.datetime.now()) + " : " + " start")
print('==================================================')
engine = create_engine('postgresql://postgres:password@localhost:5432/dbname', use_batch_mode=True)
df = pd.DataFrame()
size = 300000
df['id'] = range(0,size)
df['value1'] = np.random.randint(0, 100, size=size)
df['lon'] = np.random.randint(103000000, 105000000, size=size)/1000000
df['lat'] = np.random.randint(30000000, 35000000, size=size) / 1000000
geom = [shapely.geometry.Point(xy) for xy in zip(df.lon, df.lat)]
del df['lon']
del df['lat']
crs = {'init': 'epsg:4326'}
geodataframe = gpd.GeoDataFrame(df, crs=crs, geometry=geom)
time1 = time.clock()
print("生成: %f s" % (time1 - start))
geodataframe['geom'] = geodataframe['geometry'].apply(lambda x: WKTElement(x.wkt, 4326))
geodataframe.drop('geometry', 1, inplace=True)
time2 = time.clock()
print("修改geometry: %f s" % (time2 - time1))
geodataframe.to_sql('test1', engine, if_exists='replace',index=None,
dtype={'geom': Geometry('POINT', 4326)})
time3 = time.clock()
print("插入数据库: %f s" % (time3 - time2))
print('==================================================')
end = time.clock()
print(str(datetime.datetime.now()) + " : " + " end")
print("read: %f s" % (end - start))整个代码大体分为三部分:
- 首先生成包含包括经纬度、id和value1等列的pandas,再加入WGS84投影转为geodataframe
- 第二步是将geodataframe中的geometry转换格式,由于geopandas中使用的是shapley的point格式,而PostGIS中使用的是geoalchemy2中的point(或者说插入数据需要使用geoalchemy2格式)
- 第三步是将geodataframe插入PostGIS中,由于geopandas是基于pandas的,可以直接使用to_sql()方法
n的取值分别取了10000,50000,100000,300000,600000,每个数据n做了五次插入操作取平均时间,用时如下:
| 点数 | 第一步用时(秒) | 第二步用时(秒) | 第三步用时(秒) | 总时(秒) |
|---|---|---|---|---|
| 10000 | 0.1026874 | 0.680406 | 0.7250086 | 1.508102 |
| 50000 | 0.482665 | 3.4194326 | 3.1843962 | 7.0864938 |
| 100000 | 0.9553178 | 7.1201478 | 6.0992024 | 14.174668 |
| 300000 | 2.8992882 | 20.3128242 | 20.0280164 | 43.2401288 |
| 600000 | 5.8130978 | 41.9948676 | 34.2658338 | 85.6515864 |
我们可以用图表查看趋势 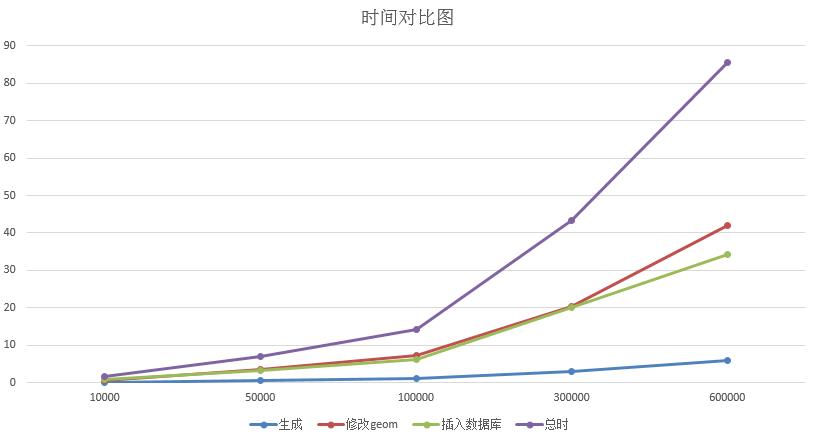

显然第一步花费的时间最少,第二步与第三步的时间基本持平。第三步的时间与to_sql()效率相关,而插入PostGIS采用了sqlalchemy 的create_engine,该包在1.2版本上加入了use_batch_mode方法,设置use_batch_mode=True能加速插入速度。
第二步的时间是我一直想削减的时间,它随着数据量的增大而超越了第三步的时间,实际上是因为它对每一个空间点都执行了WKTElement(x.wkt, 4326)操作,就是转换了geom类型,从代码上看很简单,但是从运行时间上看是一个阻碍,国外有另一种插入代码可以跳过这个步骤,但是这种插入只能插入一次,如果想下次为该表追加内容就会报错,具体可以看Write GeoDataFrame into SQL Database,如果有哪位知道削减这一步时间同时能保持表的追加,还请不吝赐教。
2018-3-10编辑更新
关于快速导入空间数据可以使用copy功能,参考我的博客“PostGIS快速导入大量点空间数据及最近邻要素跨表查询”
转载自:https://blog.csdn.net/u010430471/article/details/79200155



