空间数据挖掘与空间大数据的探索与思考(六)
接下来我们看一下我在实际工作中的遇到的一些与空间数据挖掘与空间大数据有关的案例。
客户告诉我,他有一个很简单需求:
(虾神每次听见“简单”这两个字,就瑟瑟发抖,曾经有个朋友问我会不会做网站,我说会一点点,然后他马上就说:“我有一个很简单的需求,你帮我做个百度那么简单的网站就行……就是一个输入框一个按钮……然后搜啥出来啥就行。……这么简单的要求,给你500块钱够不够?”


我说,你是不是在后面漏掉了一个亿字?百度的市值现再差不多是950亿美元。。。你给我500块钱让我做一个……


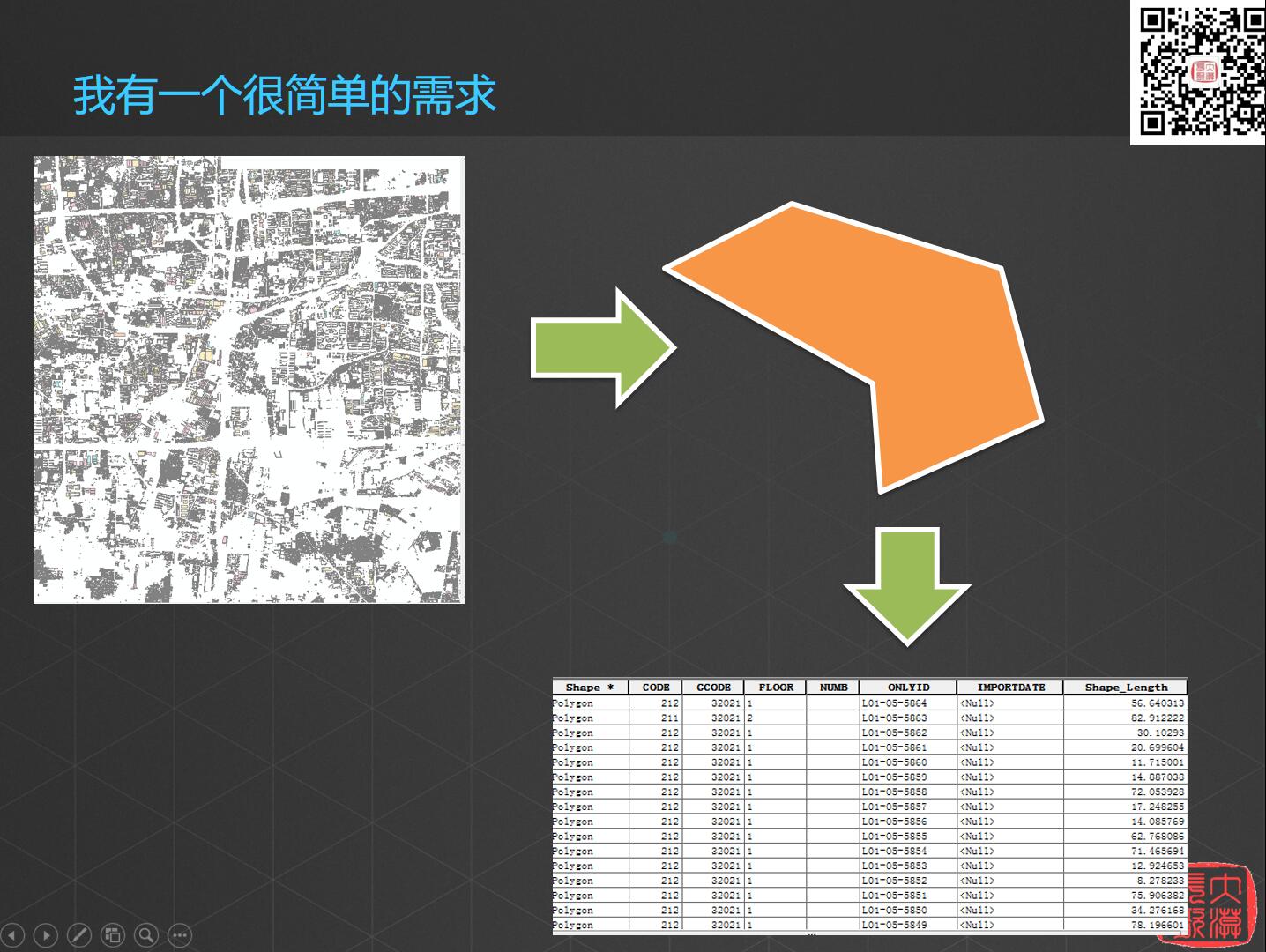

就是我现在有很多建筑物,我现在要画一个多边形,你告诉我个多边形里面包含了多少建筑物就可以了。
这样一个功能,很简单吧……你看看大约需要多少时间呢?作为GIS最基本的功能,所以这时候,我觉得,大约0.7秒差不多了吧。
所以,这么简单的问题,就交给你了。我们现在想做一个公交覆盖人群的分析,想了解北京市的每条公交线路覆盖了多少居民区,也就是在每个公交车站的一公里、两公里、三公里范围内有多少居民区。
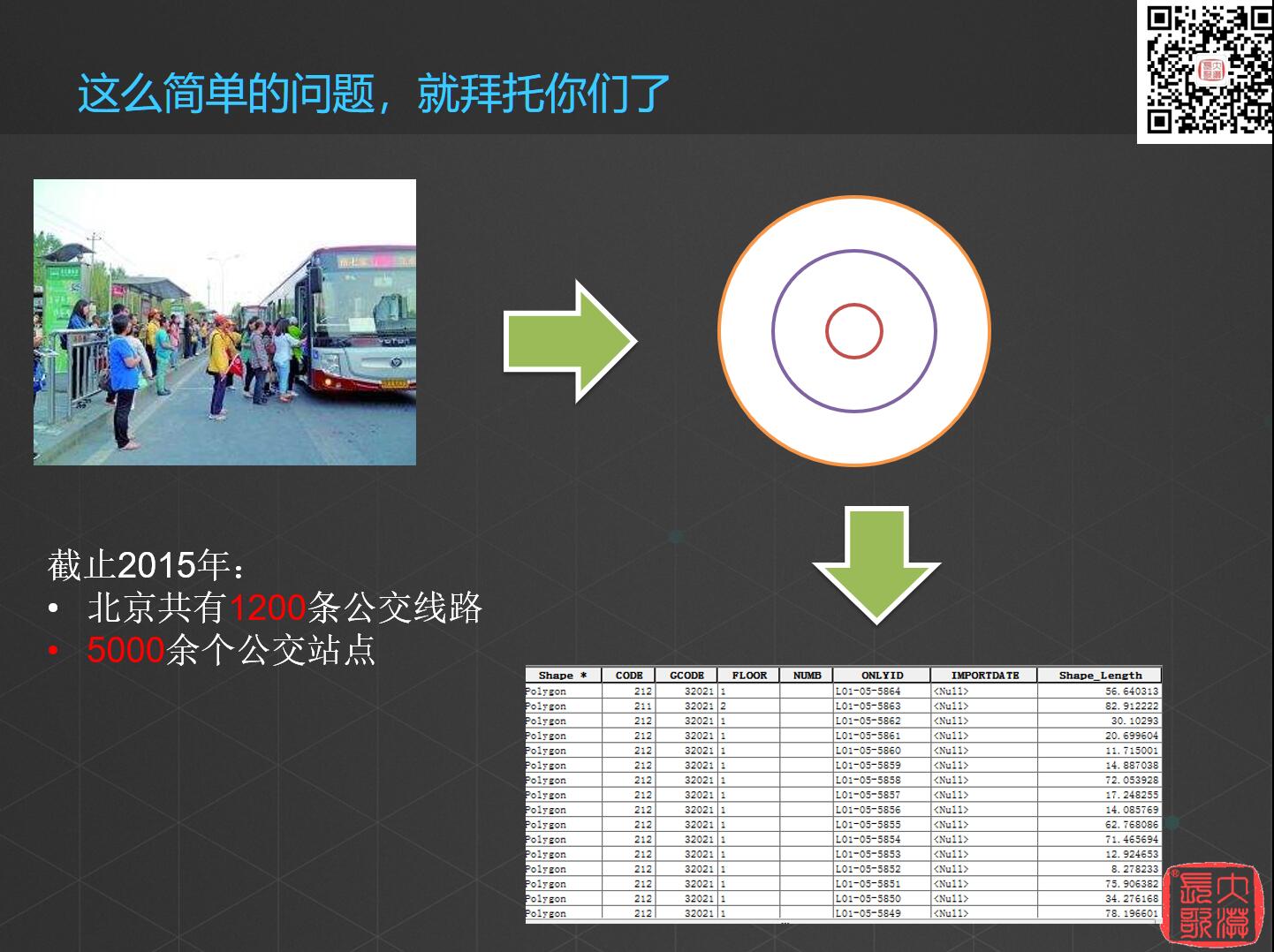

已知截止2015年,北京市共有1200条公交线路,5000余个公交站,那么需要画出15000个圈来计算覆盖了多少居民区。
如果用传统的计算模式,一个区域0.7秒,15000个区域,就需要差不多3个小时的时间……好吧,这种事情也不经常做,花一个下午做完,忍了。
所以这件事做完了,那么下面的问题也都是一样的简单,交给你们了……我们把北京市划分成186000个格网,来计算一下每个网格里面的建筑面积,用以求出北京的建筑密度……
然后我们手上有二调的土地利用现状图,一共把北京划分成了724000个地块,现要计算每个地块里有多少建筑面积……嗯,当然,这种小问题,越快越好,如果能几分钟或者几十秒就完美了……


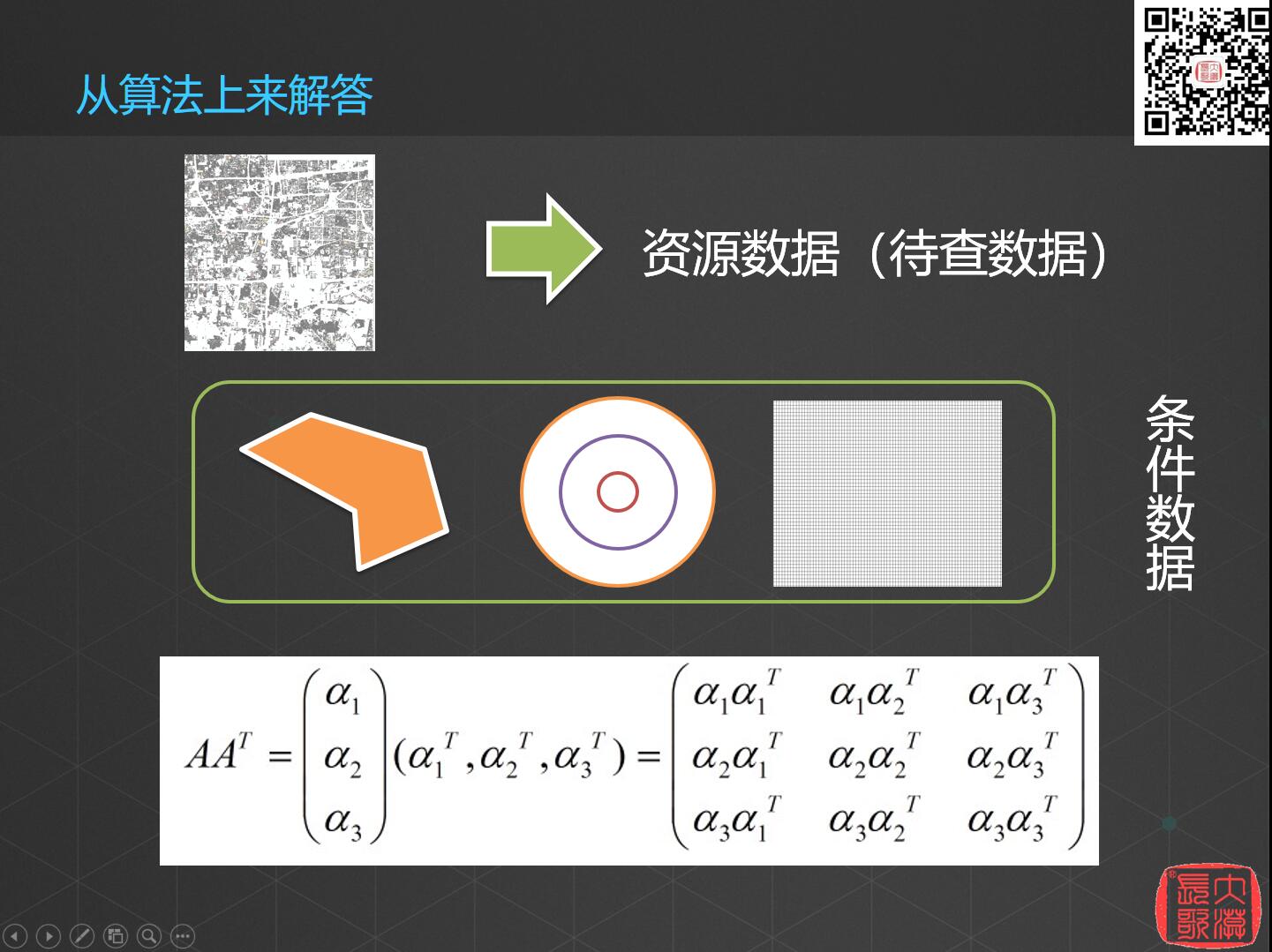
看到这种需求:


这种情况,我们实际上可以从算法上解答一下,地图等原始数据我们称为资源数据,所有的数据优化(无论是做索引,还是查询、分析的算法优化)都是在此基础上;第二类称之为条件数据,上面案例中的多边形区域、圆圈和划分的地块都是条件数据。那么如果我用500万条数据对70万个地类图斑进行计算,计算的复杂程度是几何级数的增长,正如行列式的计算一样,两个向量进行相乘,最后会算出来一个极其庞大的矩阵,而且还是不可分的。

所以这种情况下,如果要用传统线性方式进行计算,计算开销几乎不可以接收,那么如何提高计算效率,解决这个问题呢?
现在主流有三种解决方案,分别为矩阵运算、多线程运算和分布式运算。
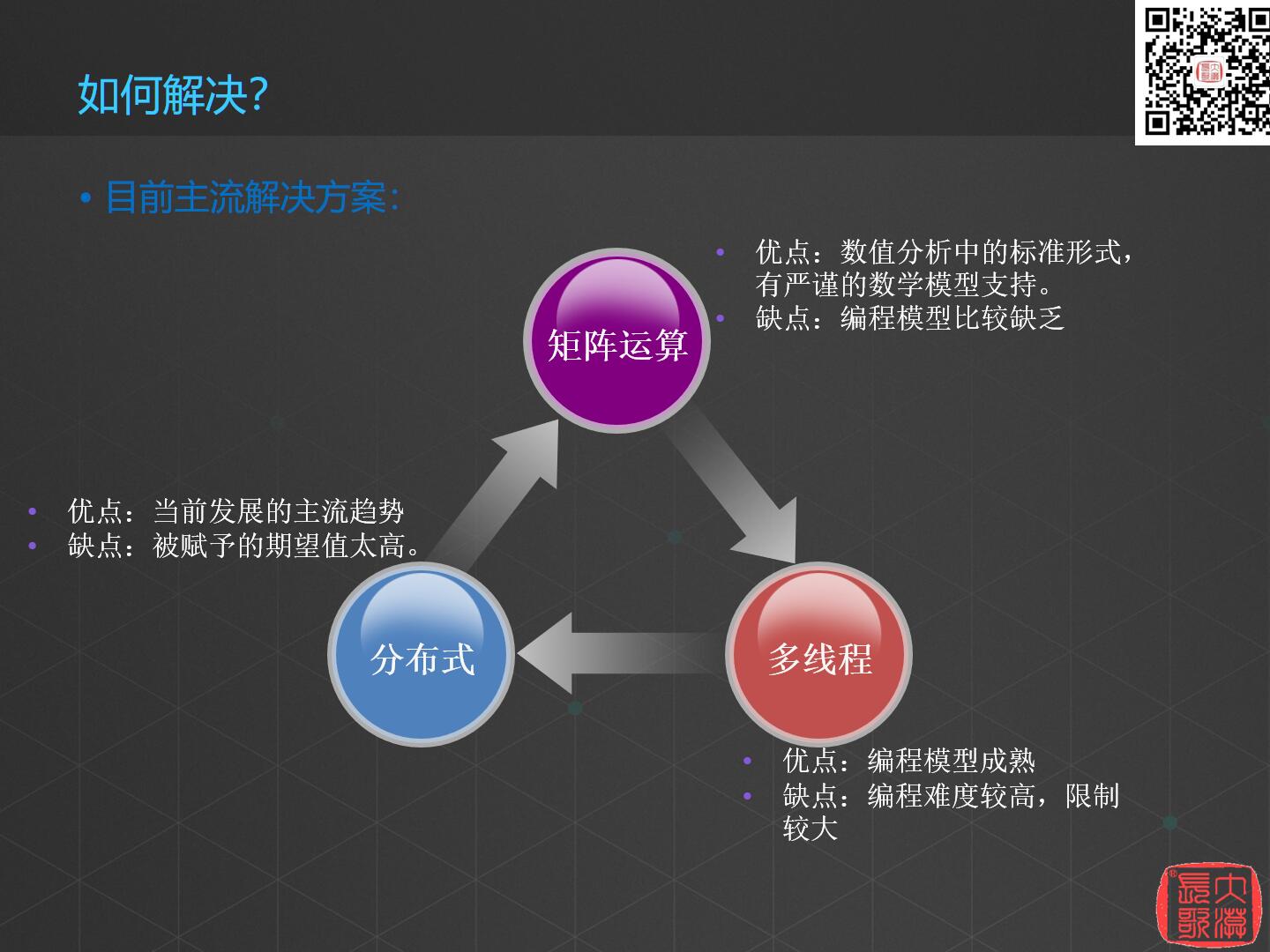

矩阵运算是数值分析的标准形式,有严谨的数学模型支持,缺点是编程模型比较缺乏,我写了十几年的代码,真正用到矩阵运算的代码非常少。
多线程方法的优点是编程模型成熟,任何一种语言都可以用多线程,缺点是难度较大,限制较高,我在实际工作中也很少写多线程代码。
第三种分布式方法,优点是符合当前发展的主流趋势,缺点是被赋予的期望值太高,使用分布式运算要从核心的需求和真正解决的问题入手。
那么被我们赋予了很大期望的分布式运算是不是就是为了速度而存在的呢?在讲速度的时候,实际上我们先要谈效率问题:
举个例子,把一批数据从北京运到广州,第一种方式是宽带,速度很快;第二种是快递,把数据加载到硬盘寄过去。如果数据只有100KB,发邮件就可以了;如果是100MB,可以先传到云盘上让对方下载;当数据到了100GB的时候,使用宽带也能传过去;但是如果是企业要搬迁,有100TB的数据甚至100PB的数据要迁移,这时候就只能选择交通运输。
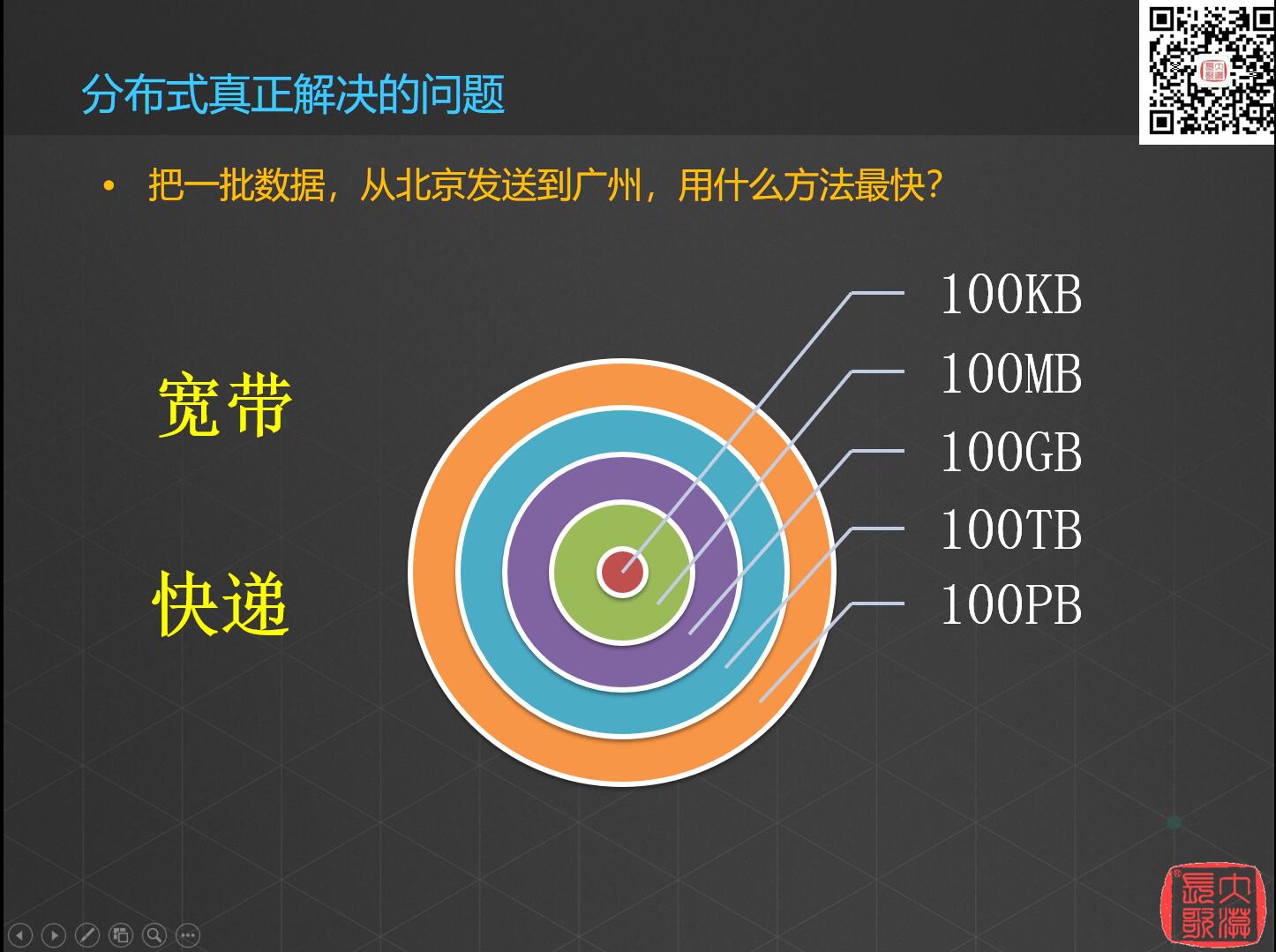

所以亚马逊就能提供这样的服务,当你的数据量太大的时候,亚马逊会开着一辆卡车到你的公司,把你们公司的数据通过光缆导入到卡车上面的硬盘存储器中,然后开着卡车把这些数据运送到亚马逊的数据中心去。这个例子就说明任何一种解决方案都是有其应用的领域的,要单纯论速度,卡车怎么也快不过宽带,但是在一定情况下,要是论效率,则不然了。


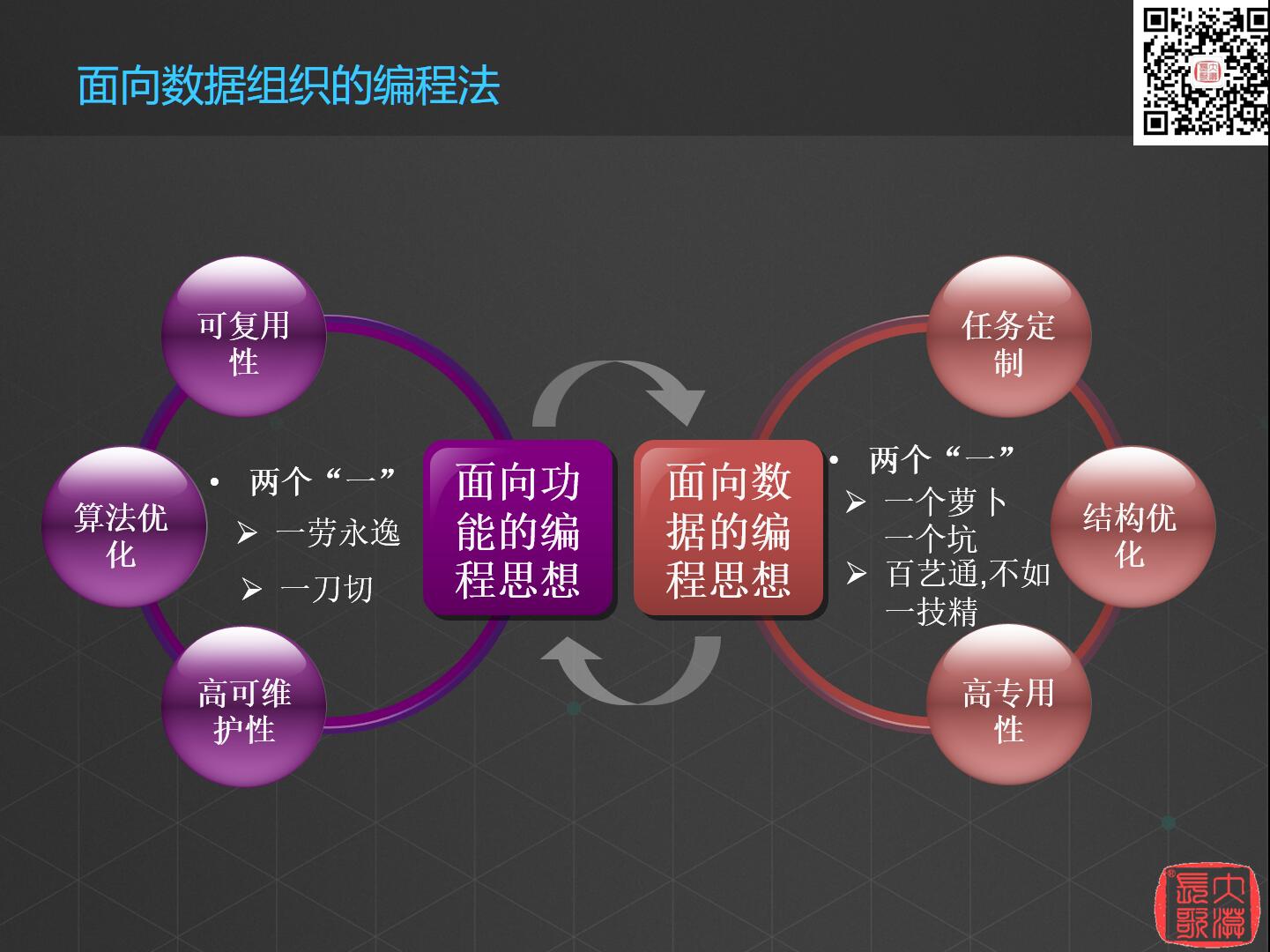
在软件工程界,这么多年以来,我们一直都在讲究功能性的编码,下面给大家介绍一种最新的编程法——面向数据组织的编程法,毕业以后有立志于做数据科学家的同学可以关注一下这种编程方法。
传统的编程法我们称之为面向功能的编程思想,实现功能之后,我们还需要对这个功能进行复用。面向功能的编程最讲究的就是算法优化,还要有高可维护性。这种编程思想有两个“一”,即“一劳永逸”与“一刀切”,“一劳永逸”是指写一次代码到处运行,“一刀切”是指用一种方法去解决所有问题。现在提出了面向数据的编程思想是因为在工作中有很多代码实际上只运行了一次,处理完要解决的问题这份代码的生命周期就结束了,这种新的编程思想是任务定制型的,最重要的是讲究结构的优化。
Spark的编程语言Scala就是面向数据组织的编程语言的典范,Scala甚至可以重写for循环,可以根据自己的数据结构去定义自己的for循环以达到最优,它还具有高专用性,很多方法可能是用完一次就不再用它了,所以他具有能够快速编写脚本的能力。这种编程思想也有两个“一”,即“一个萝卜一个坑”和“百艺通不如一艺精”,不用维护所有地方都能跑的代码,写一次代码分析完这个任务就结束。这样代码就能写得很快,这也是为什么Python这种语言这么流行的原因。

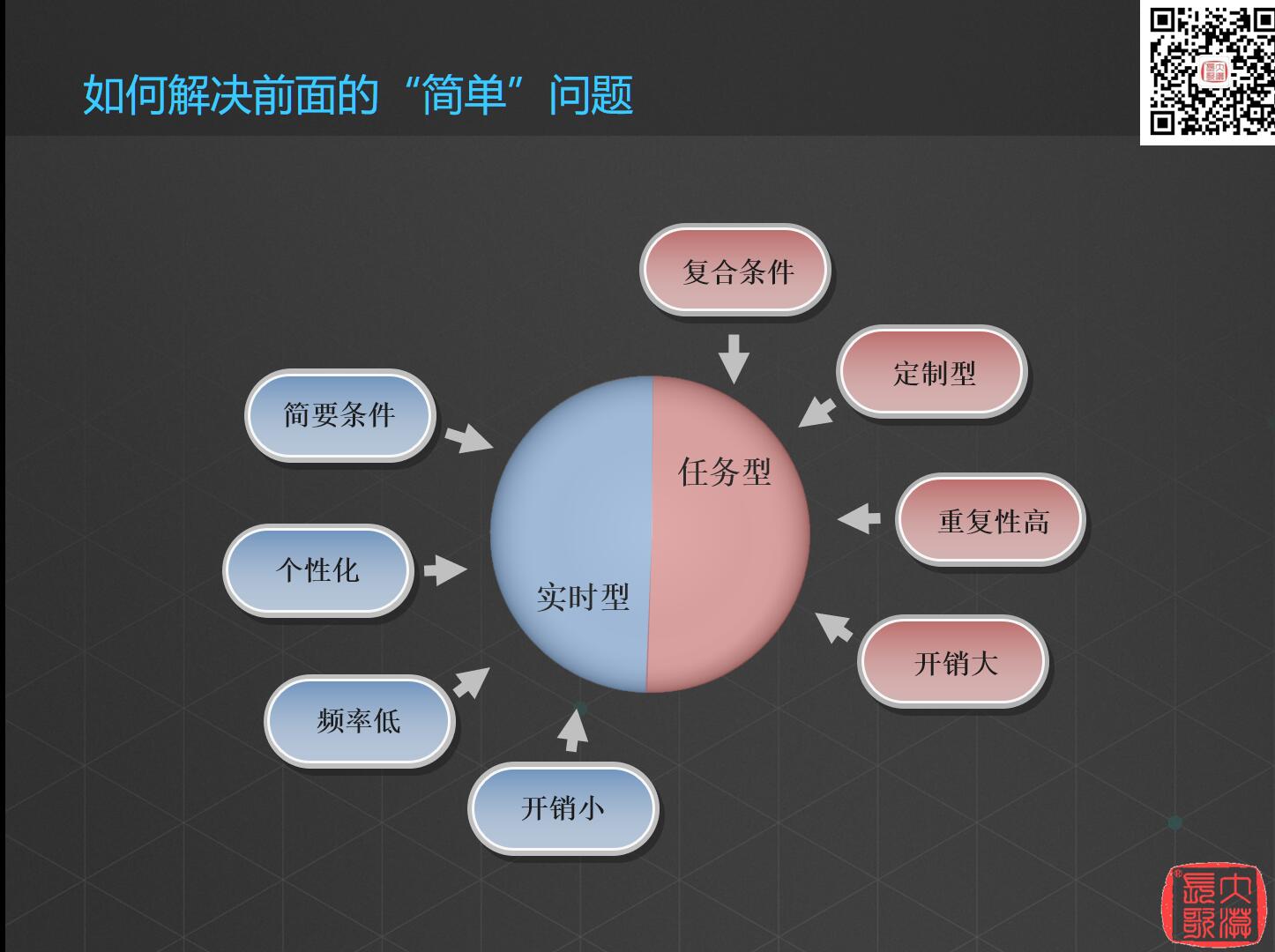
那么针对前面的三个“简单”问题,我们的解决方案可以分为实时型和任务型。
实时型有简要条件、个性化、频率低、开销小等特点,这种方案用时少,实时需要就实时计算,比如第一个问题求多边形区域内的居民区数量就可以用实时型解决方案。
任务型方案有复合条件、定制型、重复性高、开销大等特点,比如对北京市的七十多万个地块做分析,这样一年才做一次的事情,就不能要求在两分钟内做完,跑一个星期留下结果数据就行了。

当然,还可以使用中间数据来解决一些问题,我通常称为速度与精度的平衡策略。这是北京市出租车的GPS记录点,基本信息有经纬度、车号等。
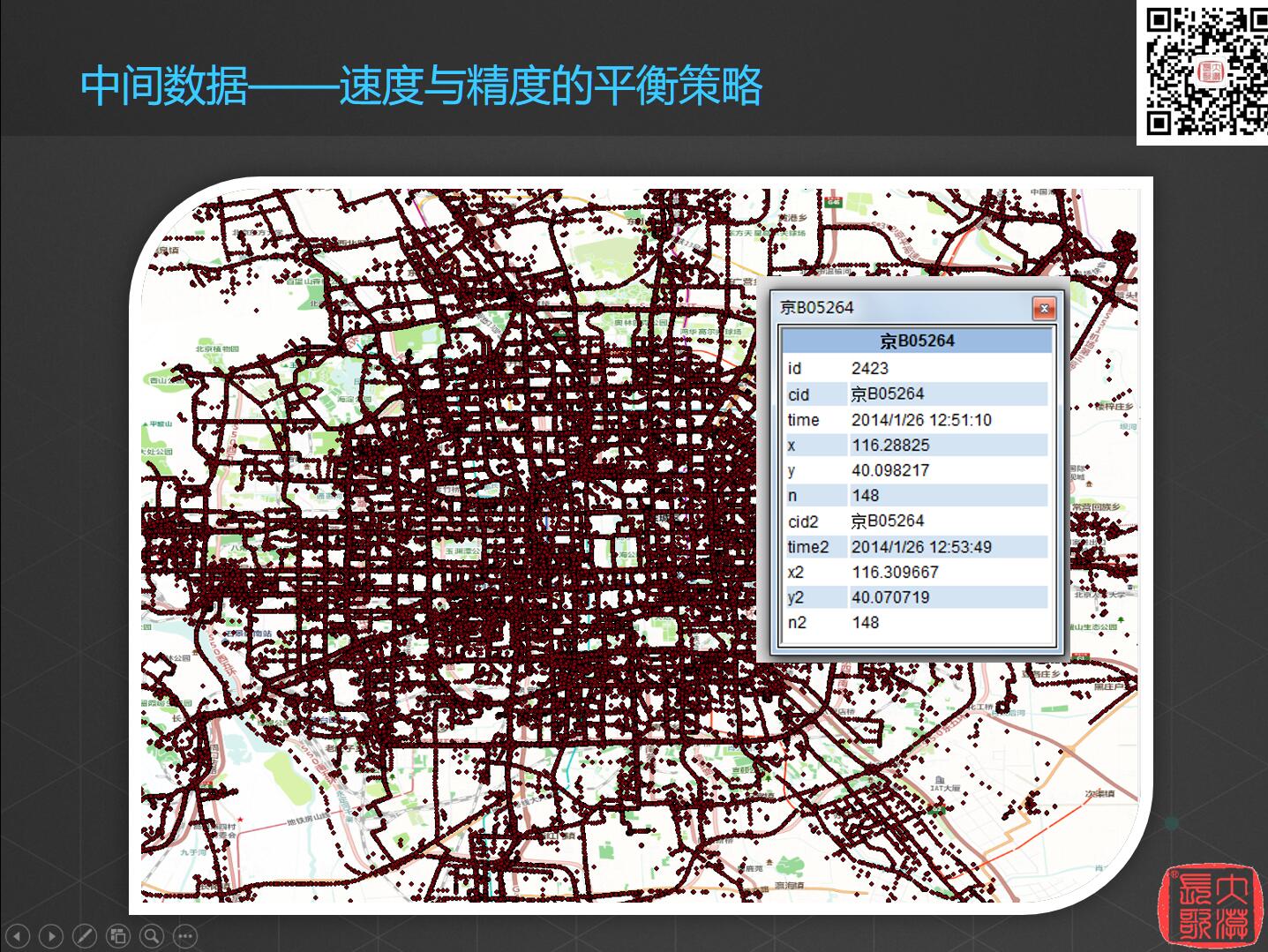

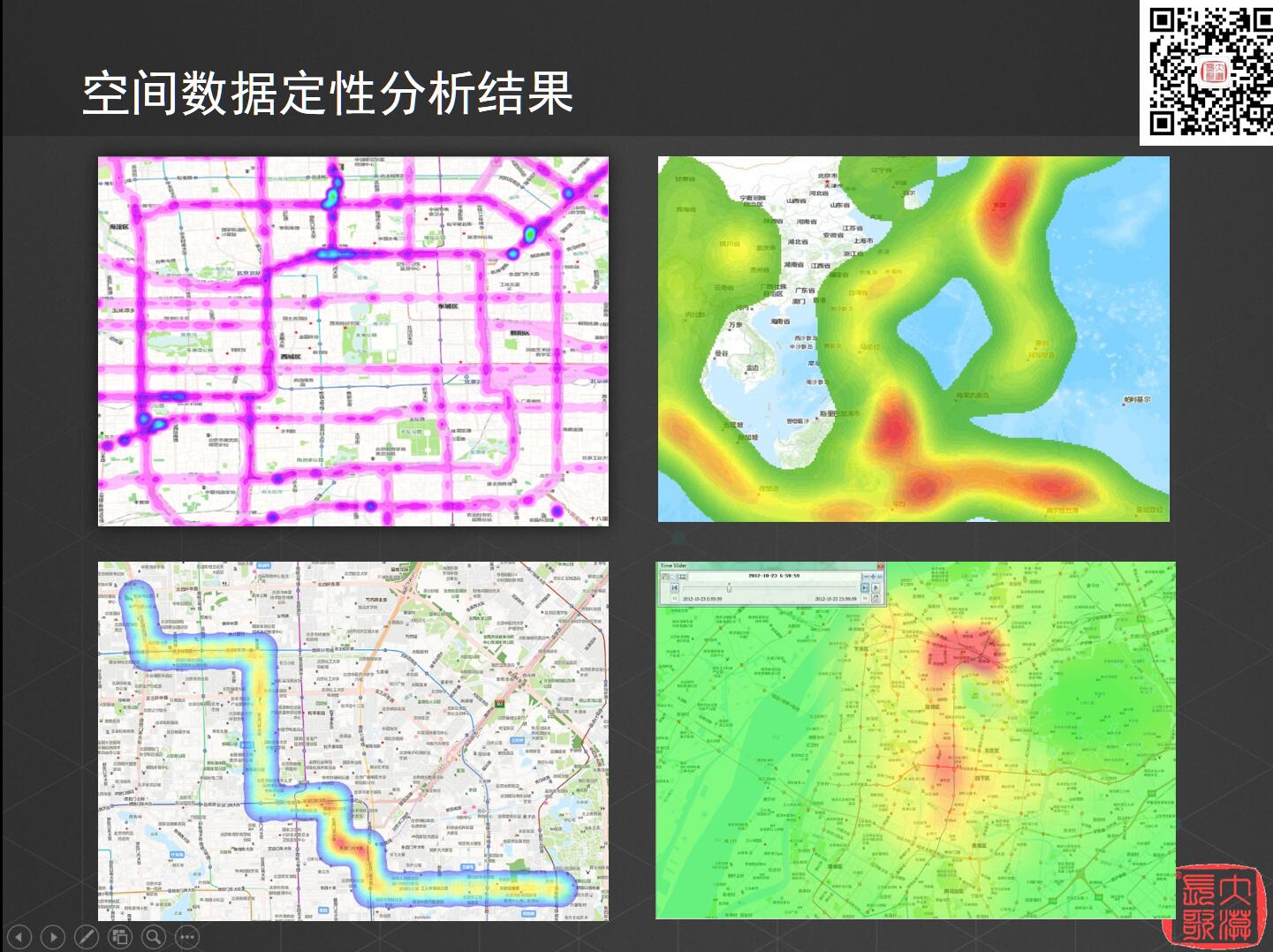
现在要知道哪个地方点比较密,实际上你需要的不是每个点的实际意义,单独一个点是没有任何意义的,只有形成一个区间或者一条线才有意义。所以需要进行网格化提取,把北京市的关键道路提取出来,用网格化的方式把每个点放入格子中以形成热点区域。由此可以很明确地可以看见哪些地方车流比较多,也就是说我们只需要对数据进行定性分析。

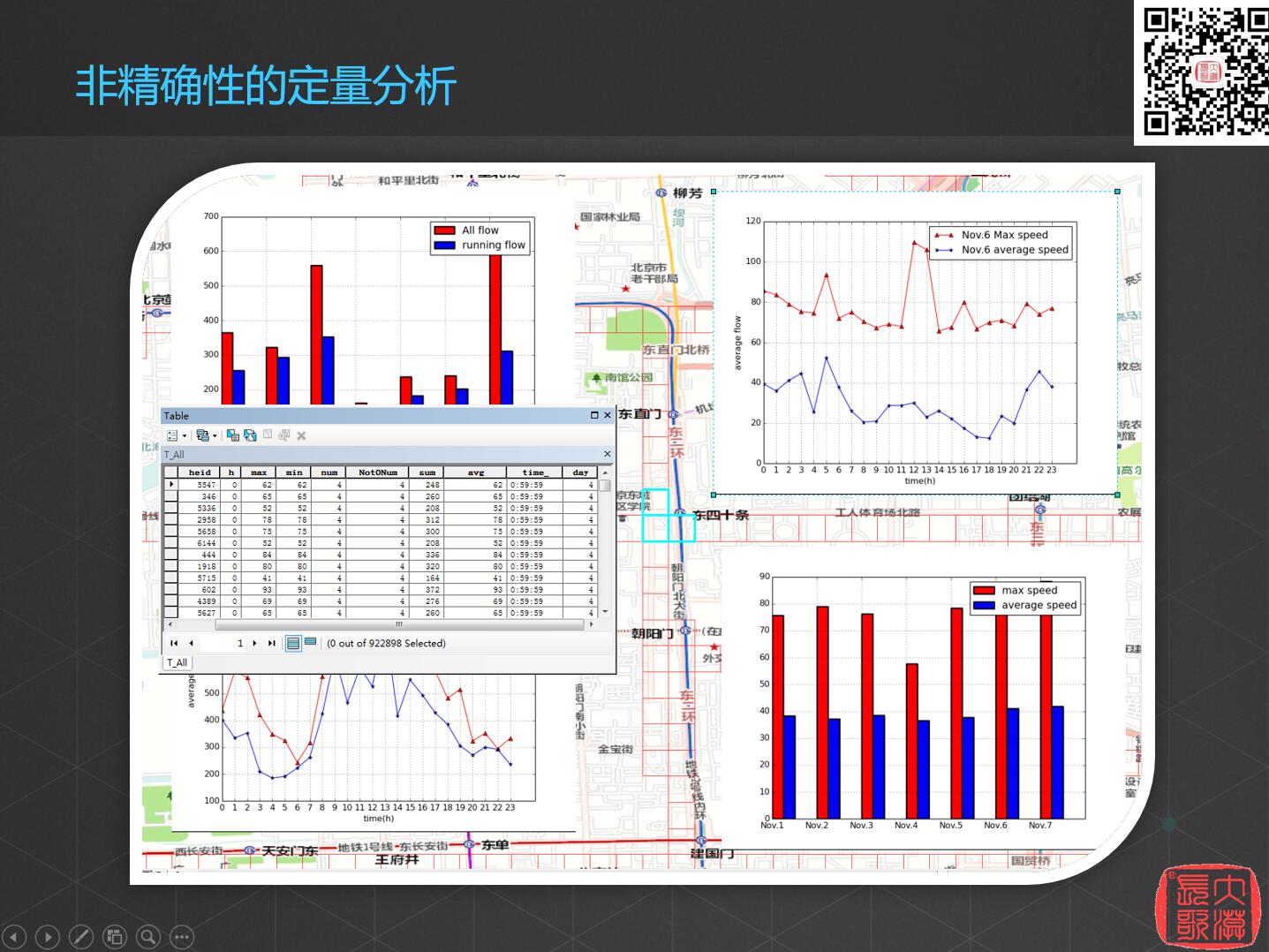

转载自:https://blog.csdn.net/allenlu2008/article/details/79863623