白话空间统计二十一:密度分析(四)
白话空间统计系列断了好久了……虽然写了很多其他的文章,但是有同学问,还是系列性的文章效果比较好,当然这些文章大部分都能分开来读,没有啥前后联系,但是系列文章最大的特点就是能够形成知识体系,无论是对于写的,还是对于读的,都有很大的好处。
好了,继续写密度分析。密度分析是我写的白话空间统计里面最长的单篇了,正剧写到这里是第四篇,番外写了两篇,但是预计起码还有好几篇才能写完,有时候想,干脆就直接叫做白话密度分析好了……可以开一个大系列。
好了,闲话少说,进入正题。(关于密度分析其他的内容,请查阅以前的文章)。
前面说了很多基本原理,但是可能大家看完之后就一个感觉:懂的说懂的,看不懂的仍然看不懂……好吧,今天虾神照样用画图的方法来说说核密度的基本原理。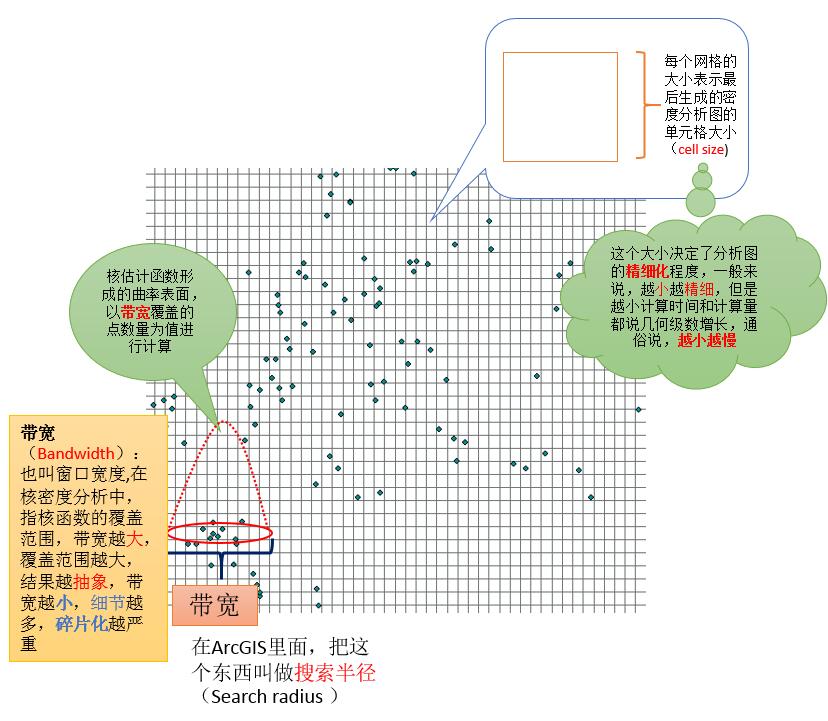
首先我们来看看不进行属性加权的核密度分析(仅仅使用空间信息进行核密度分析)。

针对一下两个参数(cell size和bandwidth),我们通过下面的图来对比一下:
数据:美国的城市(区)位置信息。
当搜索半径为2度(1度约108公里左右)的时候,生成的结果如下:明显的看出美国城区密度中心主要有下面几个:东部的纽约城市圈、中部的芝加哥城市圈、西部的旧金山城市圈和洛杉矶城市圈。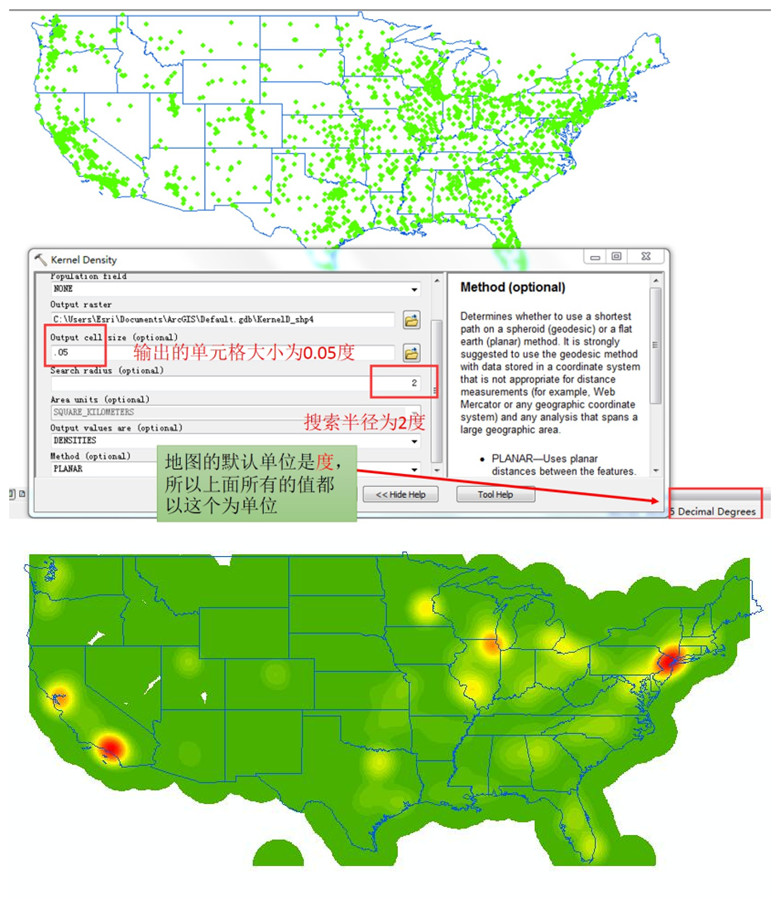

当我们的搜索半径扩大到5度(500多公里)的时候,东部的纽约城市圈和芝加哥城市圈还能勉强分开,但是加州的旧金山城市圈和洛杉矶城市圈就已经连成一体了。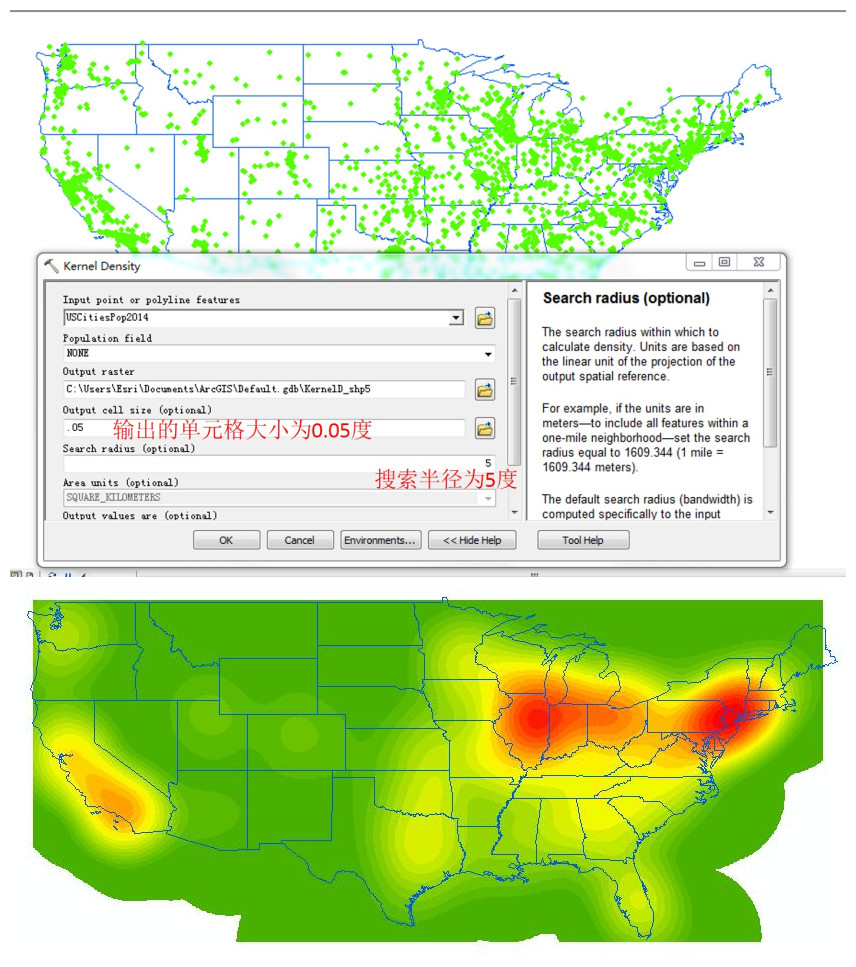

当我们把搜索半径扩大到10度(1000多公里)的时候,美国整体就变成了两个热区:东部和西部。
结论:当我们的搜索半径越大的时候,所能表现出来的结论越粗略和抽象,越能表现出整体性的趋势。而搜索半径越小的时候,细节程度越高,越能显示出局部性的趋势。

如何有效的选择搜索半径,就需要看你研究的空间尺度了,这是一个仁者见仁智者见智的过程。
以为上面主要讲的是无属性加权的,下一节继续讲属性加权的密度分析。
待续未完。
转载自:https://blog.csdn.net/allenlu2008/article/details/53198604