白话空间统计十四:高/低值的聚类(上)
从上一篇讲零假设开始,大家就都知道又要进入各种神奇的统计学理论阶段了,但是因为吴道长的提醒,所以我尽量的不写成白皮书这种官方味道十足的东西。
今天我们来讲空间自相关的一个进阶衡量方法:高/低值的聚类。
以前都说了,空间数据的关系无非就三种可能——离散、随机、聚集,如下:


那么我们拿到数据之后,首先确定离散还是聚集,因为随机就没啥价值。只有确定了之后,才能绝对我们怎么去对付他,是清蒸还是红烧,或者是凉拌,都要看原料的。
至于如何确认,我们以前也讲了莫兰指数这个东东,当然,伴随着的肯定还有P值和Z得分神马的,有兴趣的同学,请查看以前文章。
那么拿到数据,确定由聚集的可能之后,又会发生什么事情呢?
我们继续看下面的例子:
继续来抛硬币:


一次性抛出16枚编好号的硬币,结果如上图。我把结果用红圈给圈出来了,大家就很容易的看见发生了聚集,而且这次试验的结果主要是反面发生了聚集。
所以,在我们发现了数据有聚类的可能性之后,我们还可以进一步的分析,到底是哪一类数据发生了聚集,这种能够判定是哪一类值产生了聚类的,就叫做“高/低值聚类”分析。
下面进入历史科普实践,这种用于判定高/值聚类的方法,最早是由美国乔治敦大学麦克多诺商学院(McDonough
School of Business)的J. Keith Ord和圣地亚哥州立大学地理系的ArthurGetis两人提出,所以,这个算法通常由被称为:Getis-Ord General G分析。就是下面的两位帅哥(我一直对研究算法的人满怀敬意):


与硬币只有两面不同,数据是可以划分为高值和低值的,如下图:

在前面衡量空间自相关的时候,用的参数是Moran’I(莫兰指数),那么在衡量搞低值聚类的时候,用的也是一个指数,这个指数叫做 General G 指数。
General G
指数与莫兰指数一样,皆是一种推论统计,即你把数据拿到之后的下一个步骤。比如你相亲时候,第一次把妹纸相片要到的时候,首先要做的自然就是看看是不是符合自己的审美观了,然后就是找找是否有PS的痕迹,通过小细节来想象一个下这个妹纸有哪些爱好性格啊之类;这种利用有限的数据来对整体情况的特征进行估计的过程,就是推论统计。
通过分析之后得到的结果,都会在零假设(以瞎猜为背景)的情况下进行解释。也就是说,你的计算出来的值,只是与瞎猜的结果相比较得出来的结论,并不代表真实的结果。
General G统计方法,认为零假设(瞎猜)是不存在聚类的。当你进行General G方法进行计算的时候,会得出一堆的值,如下:
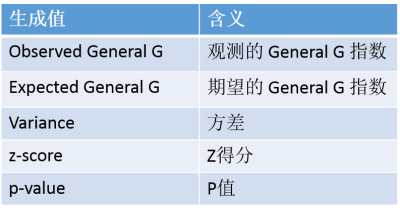

Z的分和P值和方差是啥意思就不解释了,大家回头去看原来的文章,着重解释一下观察General
G指数和期望General指数是什么东西。
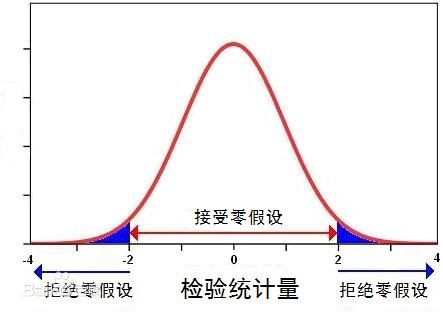
首先,还是要看看数据是否有意义,因为P值代表了你这份数据是不是随机的,如下图所示:
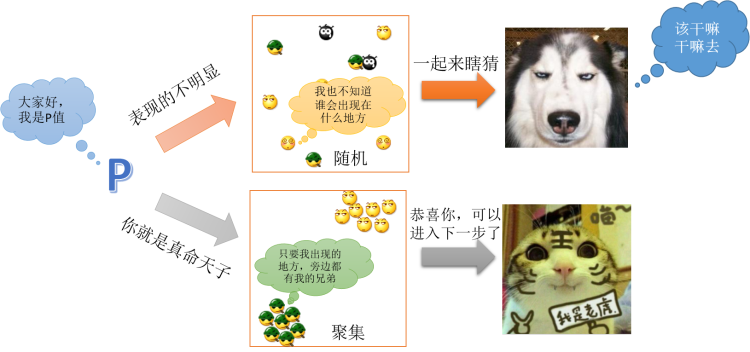

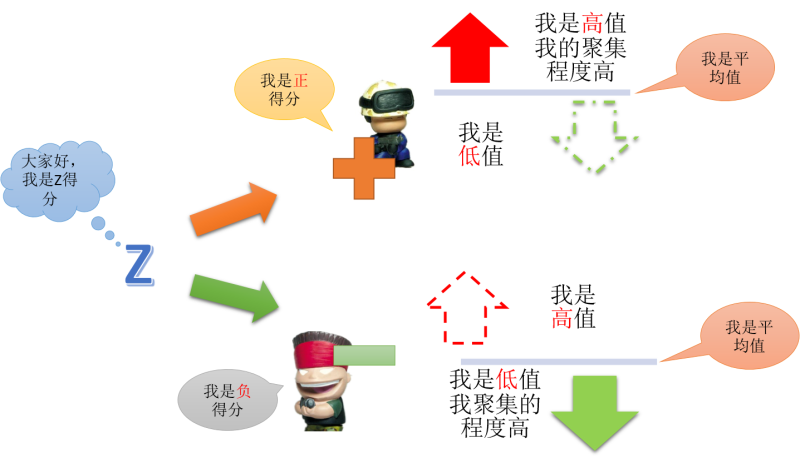
P值就决定了你这份数据是否具有分析价值,如果我们能够进入下一步,那么Z值就变得重要起来。与空间相关性里面的Z值不同,在General
G统计的计算中,Z值的正负符号是有意义的,如下:

看到这里就会有人跳出来了,你的观察General G指数和期望General
G指数哪里去了?既然Z值都已经把你要高/低值聚类都标示出来了,这个两个指数还有啥用?
别急,继续往下看。
我们开始说了,General G方法,是用来探索高\值聚类的方法,那么这两种指数也是用来衡量到底是发生了高值聚类还是低值聚类的。
单独一个指数是没有什么意义的,既然他给了两个指数,是表示,让你来进行比较的。在算法上,只要Z得分是正数,那么一般来说观察指数就要大于期望指数,而如果Z得分是负数,那么期望指数就要大于观察指数,如下:
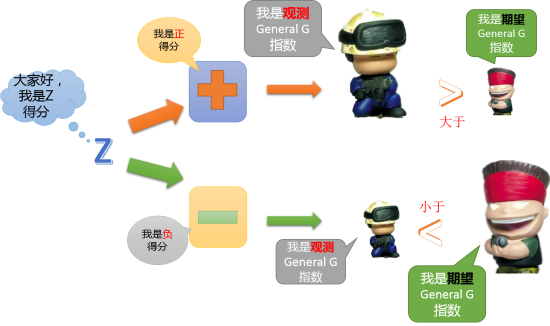

那么把两个图组合起来,就得到了如下结果:
Z得分为正——观察General G指数大于期望GeneralG指数——数据在高值区域聚类。
Z得分为负——期望General G指数大于观察GeneralG指数——数据在低值区域聚类。
但是,正如每个人小时候都被其他的熊长辈挑拨离间过——“你是喜欢粑粑还是麻麻?”往往把小孩弄得不知所措,而父母也会教小孩如何对付这些熊长辈“说‘都喜欢’”,然后皆大欢喜一样。一份数据如果同时在高值和低值区域都表现出了聚类,怎么办?
那么很容易出现的就是观察GeneralG指数和期望General
G指数相等的情况,那么这种情况用官方的话说,就是“高值和低值同时聚类时,它们倾向于彼此相互抵消。”如下图:


遇上这种高低值全部都聚类情况,基本上就可以直接放弃使用这个工具了,改用空间自相关工具即可(Globe Moran’ I)。
所以,很明显的看出,这个工具主要是去寻找高值或者低值有其中一方发生聚类的时候,才能发挥出他的价值。
(待续未完)
转载自:https://blog.csdn.net/allenlu2008/article/details/47998991