白话空间统计二十一:密度分析(二)
白话空间统计二十一:密度分析(二)
前文再续,书接上一回……
上一次我们讲了不管怎么去分你的尺度,都有可能产生断崖式的变化,那么有没有一种方法,让我们能够尽量避免断崖式的变化呢?最简单的就是滑动平均了:把原始数据集中的每个点当作连续的分布于一个范围内的值,然后把重叠的部分累加起来;并且鉴于全部的值加起来,要等于原始值。如下:我们把每个点以均匀对称的方式,让它在5个单位上平滑。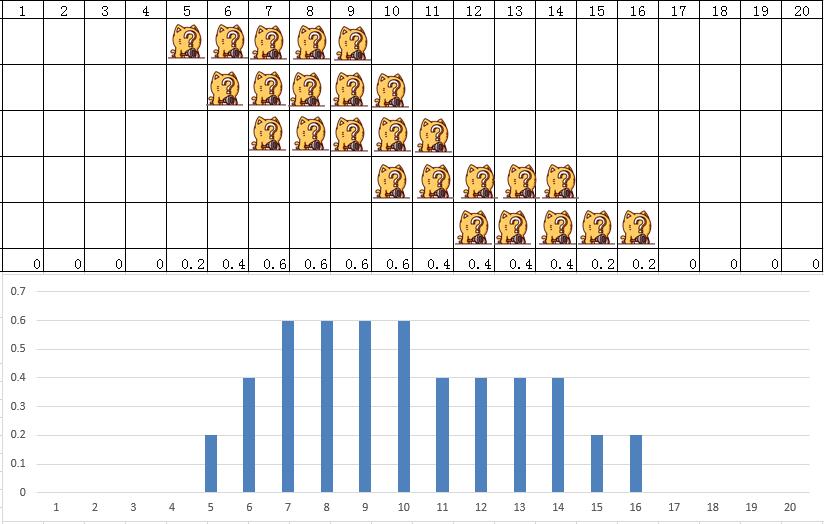
5个原始点的分配,每个点滑动平均5个单位,也就是每个单位的密度就是0.2,把它们有重合的地方累加起来,最后总得值也是等于5的。下面的直方图可以很明显的显示了这种方式的分布效果,但是带来的问题,依然是在不同区域的边界产生了跳跃:密度值从一个值到另外一个值仍然有突然变化的可能。当然,这种方式,密度始终围绕着原始值进行均匀散布,但是在值的变化过程中还还缺了一个中间值来进行表示。
解决这个问题的办法,最常用的就是通过选择一个定义明确、光滑和无界的函数来解决,也就是所谓的核(Kernel):这个核可不是威猛无比的那个nuclear……而是所谓的“核心”的核。
通常,我们用正态分布函数,把每个原始点的值绘制为正态分布曲线,就像下图的蓝色曲线部分,然后把所有的曲线下方的区域累加在一起,就得到了上面那条红色的曲线……如果想把该曲线的面积调回到1,就把这个曲线除以5就好了(绿色的线——实际上,这种调整是一种分布的规范化方式,用以有别于正态分布)。采用这种方式来进行表述的时候,通常我们把这个东东称为概率密度,当把他们扩展到二维平面上的时候,得到曲面就称为概率密度曲面而不是密度曲面了。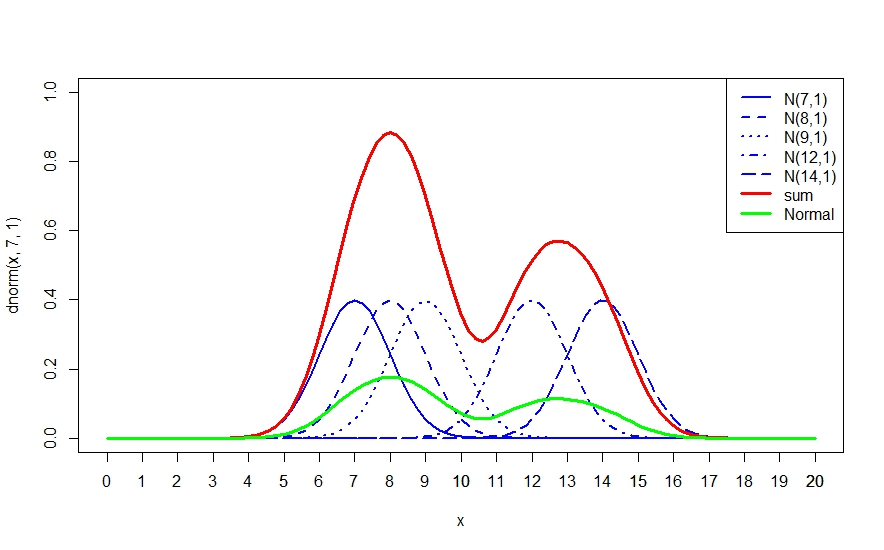
上面这张图就是所谓的单变量正态核平滑和累积密度图。
下面给出绘制这张图形的R语言源代码:大家有兴趣可以自己绘制一下,也可以调整一下效果看看
| aa1 <-curve(dnorm(x, 7, 1), from = 0, to = 20,xlim=c(0,20),ylim=c(0,1.0),col=”blue”,lwd=2,lty=1) aa2 <-curve(dnorm(x, 8, 1), from = 0, to = 20,add=T,col=”blue”,lwd=2,lty=2) aa3 <-curve(dnorm(x, 9, 1), from = 0, to = 20,add=T,col=”blue”,lwd=2,lty=3) aa4 <-curve(dnorm(x, 12, 1), from = 0, to = 20,add=T,col=”blue”,lwd=2,lty=4) aa5 <-curve(dnorm(x, 14, 1), from = 01, to = 20,add=T,col=”blue”,lwd=2,lty=5) axis(side=1,at=c(1:20)) y = aa1$y +aa2$y+aa3$y+aa4$y+aa5$y y2 = y /5 lines(aa1$x,y,lwd=3,lty=1,col=”red”) lines(aa1$x,y2,lwd=3,lty=1,col=”green”) legend(“topright”, legend = c(“N(7,1)”,”N(8,1)”,”N(9,1)”,”N(12,1)”,”N(14,1)”,”sum”,”Normal”), col=c(“blue”,”blue”,”blue”,”blue”,”blue”,”red”,”green”), lwd=c(2,2,2,2,2,3,3), lty=c(1,2,3,4,5,1,1)) |
待续未完,下次我们讲讲在二维平面上绘制核平面——讲完之后,基础部分完结,我们再进入软件部分。
转载自:https://blog.csdn.net/allenlu2008/article/details/51231492