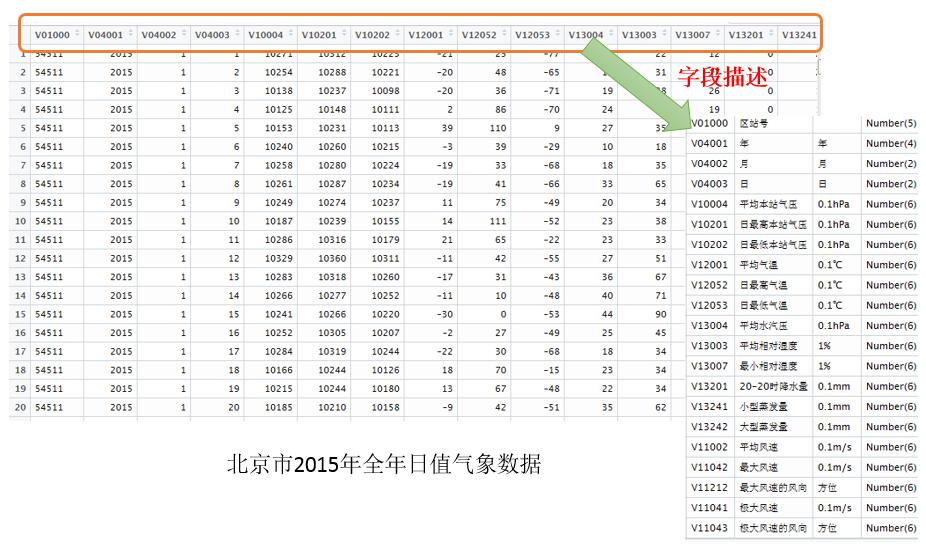
白话空间统计十五:多距离空间聚类分析 (Ripley’s K 函数) (下)
书接上一回。
多距离空间聚类分析这个工具与其他的工具计算出来的结果都不太一样。按照空间分析软件的一般规律,扔进去的是一个空间数据,那么返回的自然也是一个空间数据……
不过在前面也很多分析工具告诉我们,可能就会返回几个数据给你,比如莫兰指数,给你几个值来表示一下。这个多距离空间聚类分析工具为为什么会让我们觉得神奇呢?因为他的返回值很神奇——它会返回一堆的数字给你。
返回的值以及含义如下:

好吧,上面又变成白皮书风格了,下面是虾神标准风格说明图:
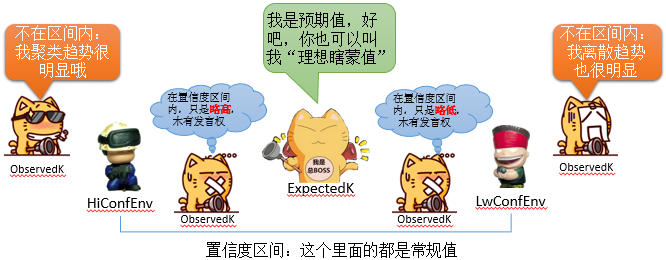
一般根据你设定的距离,会返回一堆的数据,如:
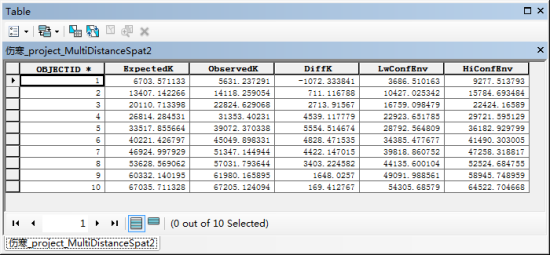
把这些数据整体画出来,就会变成这个样子
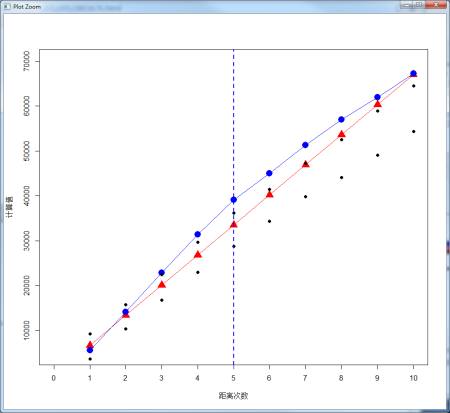
无论是从表信息里面,还是从图上,我们都可以看见,当第五次计算的时候,也就是预期K值(预期K值一般等于距离)等于33517的时候,观测K与预期K值的差距最大,聚类程度最高。
因为这个工具的交互能力比较强,也就是说,设定不同的参数,返回的内容差很多,所以今天得破例讲讲工具的各种使用参数,如下:

整个工具有11个参数,但是实际上除去默认的几个参数以外,你只需要填入两个参数就行,一个是输入的要用于计算的要素图层,一个就是输出的表格了。
下面把以下参数解释一下,简单的我就略过了。
先说说距离的选择相关的三个参数,分别是
- Number_of_Distance_Bands
距离的变化次数(递增次数) - Beginning_Distance
(起算距离) - Distance_Increment
(递增步长)
这三个参数理论上一起用的,只不过距离的的变化次数默认就直接给你是10次,而起算距离和递增步长作为可选参数。
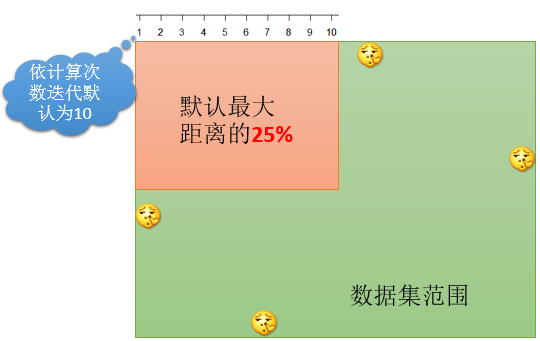
起算距离参数如果你不指定的话,系统会设定一个默认值。默认值是设定你的最大范围,在ArcGIS里面,这个默认最大距离就是整个数据范围的25%。而如果有了起算距离,那么距离增量=(最大距离
– 开始距离)/迭代值
然后我们来看看权重这个东西。
其实权重在空间计算里面,一直是个很重要的东西,还是引用毛博士语录:凡事不考虑属性的空间聚类,都是耍流氓……所以在空间分析里面,很多时候属性被体现在权重上面。
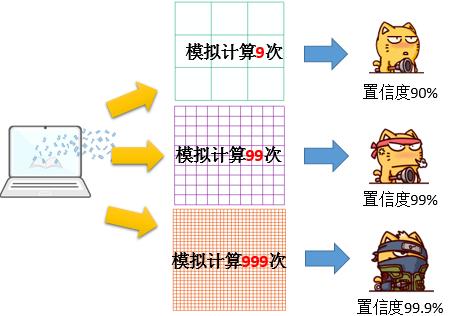
第三来看看随机模拟的次数,这个表示我们给出多少组模拟数据,来设定置信度的问题,如果你选择“0_PERMUTATIONS_-_NO_CONFIDENCE_ENVELOPE”这个参数,也就表示不创建置信区间。那么你的结果里面,就不会出现LwConfEnv和HiConfEnv这两个数据了。
那选择其他三个参数,如下:
- 9_PERMUTATIONS —随机放置了 9 组点/值。
- 99_PERMUTATIONS —随机放置了 99 组点/值。
- 999_PERMUTATIONS —随机放置了 999 组点/值。
其中:9表示 90%,99 表示 99%,999 表示 99.9%。
因为K函数有一个特点,就是对位于研究区域边界附近的要素具有统计缺漏偏差(也叫不完全统计偏差:undercount
bias ,也就电视里面经常说的“据不完全统计”……指不能完全预见统计内可能出现的各种情况,从而无法达成内容完备、设计周详的统计。)。
所以上面提供边界校正方法参数提供了解决这一偏差的方法。(查看参数说明中的第9个参数)
- NONE
如果应用这种参数,表示不应用任何特定的边界校正。但是,落在用户指定的研究区域外的点在相邻点计数中使用。如果我们的数据是从超大研究区域中收集数据,但是仅需分析数据集合边界内更小的区域,则此方法很适用。如下图:

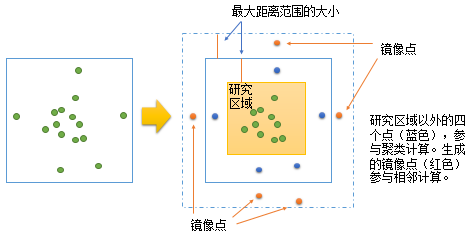
- SIMULATE_OUTER_BOUNDARY_VALUES
此方法会在研究区域边界外,创建边界内所发现点的镜像点,以便校正边附近的低估现象。将镜像与研究区域的边的最大距离范围相等的距离内的点。使用已镜像的点会使边点的相邻点估计更加精确。下图说明哪些点用于计算以及哪些点仅用于边校正。
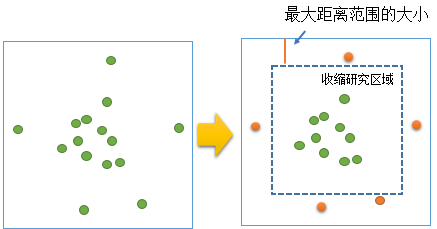
- REDUCE_ANALYSIS_AREA
此边校正技术将分析区域的大小收缩一定的距离,此距离与将在分析中使用的最大距离范围相等。收缩研究区域后,仅在为仍处于研究区域内的点评估相邻点数目时,才会考虑新研究区域外发现的点。K 函数计算期间,不会以任何其他方式使用这些点。下图说明哪些点用于计算以及哪些点仅用于边校正。
- RIPLEY’S_EDGE_CORRECTION_FORMULA
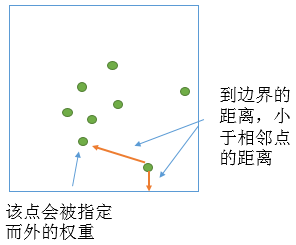
此方法检查每个点与研究区域的边的距离以及这个点到其各相邻点的距离。如果有的相邻点与所涉及点的距离比与研究区域的边的距离更远,则所有这类相邻点都将被指定额外权重。此边校正方法仅适用于形状为正方形或矩形的研究区域,或者当为研究区域方法参数选择 MINIMUM_ENCLOSING_RECTANGLE 时才适用。
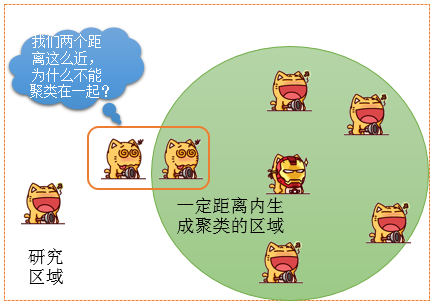
这个方法有人会问,这么复杂的方法,如此多的参数,他到底想解决的是什么问题呢?这个主要解决的边界点邻近的问题,如下图所示:
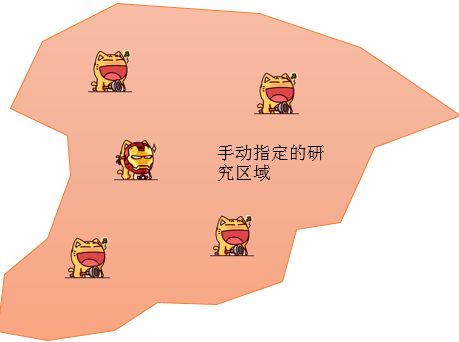
最后来看看参数10,也就是研究区域的问题。这个问题在经典统计学里面,是个很重要的问题,特别是对于K函数这种对距离很敏感的方法,那么它提供了两种限定研究区域的方法,如下:
- MINIMUM_ENCLOSING_RECTANGLE —指示将使用封闭所有点的最小矩形。如下图:

- USER_PROVIDED_STUDY_AREA_FEATURE_CLASS —指示定义研究区域的要素类将在“研究区域要素类”参数中提供。
OK,到此,所有的输入参数都说完了,最后用几句话,来说说这个方法到底有什么作用。
在上一篇文章中,其实已经讲过,距离的探索是点模式分析中很重要的一个工作,实际他的应用非常的多,如下面的几种应用:
城市里面有若干巡逻热点,如果警方要部署巡逻区域,怎么才能找到即省油,又能尽量的覆盖到所有的巡逻热点这样的分析中,就可以采用距离分析,探索每个设定的巡逻区域的最佳距离。
另外,我有一批点,我现在要用这些点生成一个缓冲区,这个缓冲区需要覆盖所有的区域,但是又要求缓冲区的距离是最小的,那么就可以通过这个工具,来找到聚类程度最高的一个距离,如下:

对照一下图,我们可以看出,聚类程度最高的数据,用于计算这类缓冲区,效果是最好的。实际数据统计图如下:

转载自:https://blog.csdn.net/allenlu2008/article/details/48176315