GIS 中的机器学习和人工智能
您可能听说过机器学习 (ML) 。但是您不确定如何在 GIS 环境中使用它。
简而言之,机器学习可以从嘈杂的数据中发现您从未想过的模式。换句话说,它是编写软件的软件。
ML 不是应用预建函数,而是通过重复看到的条件获得经验,并构建模型以应用于新情况。
例如,Google 可能会使用贝叶斯分类来过滤垃圾邮件。或者,Facebook 可能会将其用于面部识别并自动识别图像中的面部。 ML 甚至可以在每部电影中渲染尼古拉斯凯奇。
但是我们如何在 GIS 环境中使用它呢?今天就来探讨一下这个问题。请记住,如果您真的有兴趣开始使用 AI,这里有一些机器学习认证课程可以帮助您入门。
机器学习 (ML) 的类型
机器学习的两大类是有监督的和无监督的。它们都可以以各种方式应用于 GIS 应用程序。首先,两者有什么区别?
监督学习只是将数据拟合到预测函数中。例如,如果您在图形中绘制数百万个样本点,则可以拟合一条线来逼近一个函数。
无监督学习识别数据使用未标记数据的模式。例如,它需要数百万张图像并通过训练算法运行它们。经过数万亿次线性代数运算后,它可以拍摄一张新照片并将其分割成簇。
最重要的是,机器学习是关于以最佳方式解决问题。因此它会自动地自行学习并根据经验进行改进。
最近,GIS 正在将人工智能应用于分类、预测和分割等领域。两个最流行的框架是TensorFlow和PyTorch 。
1.图像分类(支持向量机)
当您查看卫星图像时,并不总是很容易知道您是在看树木还是草地……或者是道路还是建筑物。因此,想象一下计算机要知道它有多难。
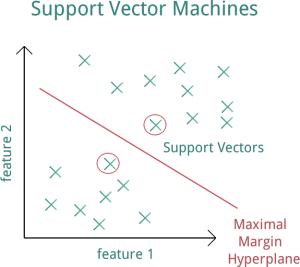
支持向量机 (SVM) 是一种机器学习技术,它采用分类数据并查看极端情况。接下来,它根据称为“超平面”的数据绘制决策边界线。而“超平面”边距向上推的数据点就是“支持向量” 。
“支持向量”很重要,因为它们是最接近对立类别的数据点。因为这些点是唯一考虑的点,所以模型中的所有其他训练点都可以忽略。本质上,您为 SVM 提供树木和草地训练样本。它基于这些训练数据构建模型,生成自己的决策边界。
现在,这种监督分类的结果并不完美,算法还有很多需要学习的地方。我们仍然需要处理道路、湿地和建筑物等特征。随着算法获得更多的训练数据,它们最终会改进以在任何地方进行分类。
2. 使用 K-means 进行图像分割和聚类
到目前为止,K-means 算法是最流行的数据聚类方法之一。在 K 均值分割中,它将未标记的数据分组为由变量 K表示的组数。
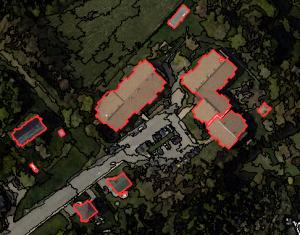
这种无监督学习方法根据特征的相似性迭代地将每个数据点分配到 K 个分组中的一个。例如,相似性可以基于光谱特征和位置。
在无监督分类中,k-means 算法首先对图像进行分割以供进一步分析。接下来,为每个集群分配一个土地覆盖类别。
但是,GIS 可以以其他独特的方式使用聚类。例如,数据点可能代表犯罪,您可能希望对犯罪热点和低点进行聚类。或者,您可能希望根据社会经济、健康或环境(如污染)特征进行细分。
3. 使用经验贝叶斯克里金法 (EBK) 进行预测
您可能知道,克里金插值法根据空间模式预测未知值。它根据变异函数估计权重。估计表面的质量反映在权重的质量上。更具体地说,您需要能够提供无偏预测和最小方差的权重。
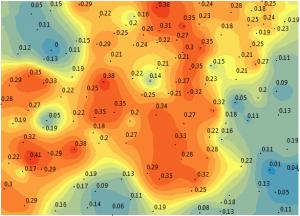
与针对整个数据集拟合一个完整模型的克里金法不同,EBK 克里金法通过对整个数据集进行子集模拟至少一百个局部模型。由于模型可以使用克里格方法在局部变形以适应每个单独的半变异函数,因此它克服了平稳性的挑战。
在经验贝叶斯克里金法 (EBK)中,它使用各种模拟反复预测多达一百次。每个半变异函数彼此不同。最后,它混合了最终表面的所有半变异函数。您无法像使用传统克里金法那样进行自定义。
最后,它输出它认为最好的解决方案。就像蒙特卡罗分析一样,它会在后台为您重复运行。如果是随机过程,你让随机过程跑完一千多次。您会看到结果数据中的趋势,并使用它来证明您的选择是正确的。这就是为什么EBK 几乎总是比直接克里金法预测得更好。
大数据的深度学习和训练过程
无论您是在 GIS 还是其他领域,机器学习都是当今的热门话题。这是关于提炼大数据集。因为如果你能让计算机检测到这些特征,它就会向你展示你从未注意到的东西。
因为数据太多,您可以从中发现内在模式。结果是一个训练有素的神经网络只有一组加权值。
当你训练大数据时,这就是你需要你能获得的所有火力的时候。但是一旦你训练了模型,它只是一个文件中有一组权重的模型……这就是为什么机器学习是人工智能的一种形式——因为你可以训练你的数据,然后将它应用到全新的事物上并预测这是什么。
总体而言,GIS 使用机器学习进行预测、分类和聚类。 AI 和 ML 仍然是不断发展的领域,每天仍在开发许多框架。