ArcGIS教程:将模糊逻辑应用于叠加栅格(一)
模糊逻辑可用作叠加分析方法,来求解诸如地点选择和适宜性模型等传统的叠加分析应用。
模糊逻辑的基本前提是空间数据的属性和几何中存在误差。模糊逻辑提供了用于解决两种类型的误差的方法,但由于模糊逻辑与叠加分析相关,因此其重点关注的是属性数据中的误差。类的定义以及现象的测量值中是属性数据中出现误差的两个主要方面。这两种误差源(尤其在类的定义中)可在将像元指定给特定类时造成不精确的结果。
分类中各个类的定义以及将现象指定给各个类时的不精确性可影响决策的制定。“模糊叠加”工具可帮助决策者通过这些不精确性制定决策。模糊逻辑重点在于对类边界的不准确性进行建模。
加权叠加和加权总和基于明确集合,其中每个像元在或不在某个类中。模糊逻辑专门用于解决各个类之间的边界不明确时的情况。与明确集合不同,模糊逻辑不是在类内还是在类外的问题;它用于定义现象是集合(或类)的成员的可能性有多大。模糊逻辑以集合论为基础;因此,您将定义可能性,而不是概率。
例如,在房屋适宜性模型中,如果坡度是输入条件之一,根据坡度值成为适合建筑物(或类)的适宜性集合的成员的可能性,将每个坡度值变换或指定一个介于 0 和 1 之间的值。值 1 表示完全确定值在集合中,0 表示完全确定值不在集合中。其他所有值表示某种可能性等级,较高的值表示较大的隶属可能性。将原始输入值变换为 0 到 1 的隶属可能性范围的过程称为模糊化过程。模型的每个条件(例如坡向、到公路的距离和土地利用类型)都将被模糊化。模糊分类工具用来将数据变换为 0 到 1 的可能性范围。
要确定最符合所有条件的位置(即在所有集合中具有高隶属可能性),将使用模糊叠加工具。当合并多个条件时,模糊叠加工具会确定像元隶属于由多个条件所定义的每个集合的可能性。例如,某一特定位置属于坡度、坡向和到公路的距离的良好适宜性的可能性是什么?
因此,模糊逻辑中的两个主要步骤是模糊化(或模糊分类过程)和模糊叠加分析。在一般的叠加过程中,这两个步骤分别与重分类/变换步骤和添加/合并步骤相关。
很多时候,某事物是否属于某一类是不明确的,而是主观性的。在人类语言中,这些不精确性通过修饰词进行量化,例如非常、略微和适中。模糊逻辑执行叠加分析更类似于自然的人类思维。事物不明确;边界可以是模糊的。模糊逻辑不是分析数据中的不确定性,而是探究类边界中的不精确性。
以下部分将介绍与数据分类相关的问题、“模糊分类”过程,以及执行“模糊叠加”分析。还将介绍模糊逻辑与二进制及加权叠加分析方法的比较,以及模糊逻辑如何整合到一般的叠加过程中。
数据分类和模糊逻辑
要对现象进行描述或排序,一般会将它们划分为各个类。土地利用类别、土壤类型、适宜性权重、道路类和植被类型均是类的示例。在明确集合中,隶属度是二进制的,现象或者在类中,或者不在类中。类边界是清晰的。但由于想法的不精确性、分类规则的不明确性、模糊性以及矛盾心理,类之间的边界不总是明确的。
例如,如果正在探究的现象是某个组中人的不同身高的关系,您可能会根据身高先将不同的人集中到各个类中。您可能从三个类入手 – 矮个、中等和高个。需要设置各个类的边界。例如,矮个的人可能是指 5 英尺(1.524 米)及其以下的任何人,高个的人可能是指 6 英尺(1.8288 米)及其以上的任何人,中等身高的人则介于 5 英尺和 6 英尺(1.6764 和 1.8288 米)之间。身高为6 英尺(1.8288 米)的人将位于高个类中。身高为 5′ 11″(1.8034 米)的人将被划分为中等身高类。两个人的身高之间仅
1 英寸(0.0254 米)之差,却位于两个不同的类中。如果另一个组成员身高为 5′ 1″(1.5494 米),第二个成员身高为 6′ 6″(1.9812 米),则会表现与上面相同的差异关系。由于分类的粗糙性,无法获得各个身高之间完整的关系。
要更准确地表示不同人之间的身高关系,可添加更多的类。例如,可再添加两个类,这样矮个将为 4′ 10″(1.4732 米)及其以下,中低个将为 4′ 10″(1.4732 米)至 5′ 4″(1.6256 米),中等身高将为 5′ 4″(1.6256 米)至 5′ 10″(1.778米),中高个将为 5′ 10″(1.778 米)至 6′ 4″(1.9304 米),高个将为大于 6′ 4″(1.9304 米)。通过类中的这种细化,可更准确地获得人的身高之间的关系。
为进一步细化,甚至可添加更多的类。无论添加了多少类,仍然存在人之间身高关系的概括。存在一些不能被划分到严格定义的类中的现象。有时,很难将现实世界分组为离散的类。
由此看来,定义类边界可以是主观的且可随现象的定义而更改。在上述定义的身高类中,假设人为成年人,很可能是男性和女性的混合形式。如果组完全由女性组成,则可能需要更改类定义。如果组由儿童组成或包含儿童,则可能需要更进一步地更改类边界。
现象的类和特征的定义描述了如何表示要建模的现象。测量误差进一步复合了分类问题。如果测量人身高的步骤的精度为正负 1英寸(0.0254 米),则误差可更改现象被指定的类。
模糊逻辑会在分类过程中对这种不精确性进行建模。在模糊逻辑中,类被定义为集合。了解集合中成员的理想值是什么,例如,房屋适宜性模型中理想的坡度值。当值远离理想值时,明确等级会减小到某个特定点,在该点处可以明确值不是集合的成员(例如,的确过陡而无法在其上构建)。
例如,在上述身高应用中,如果从三个类(矮个、中等和高个)入手,则模糊逻辑中这三个类可以重叠。
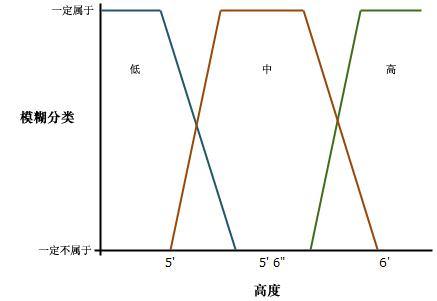
在上图中,每个类的完整隶属度为
矮个:< 5 英尺(1.524 米)
中等:5′ 3 1/2″(1.6129 米)至 5′ 8 1/2″(1.7399 米)
高个:> 6(1.8288 米)
对于矮个集合(或类),身高为 5 英尺(1.524 米)及其以下的任何人确定在小个集合内并指定为 1。身高大于 5 英尺(1.524 米)且小于 5′ 3 1/2″(1.6129 米)的任何人介于小个和中等集合(或类)之间。对于介于 5 英尺(1.524 米)和 5′ 1 3/4″(1.6193 米)之间的身高,很可能在矮个集合中。大于 5′ 1 3/4″(1.6193 米)且小于或等于 5′ 3 1/2″(1.6129 米)的身高可能在矮个集合中,但更有可能是中等集合的一部分。
通常使用模糊分类工具通过预先确定的函数执行模糊化过程。
转载自:https://blog.csdn.net/dsac1/article/details/38085165