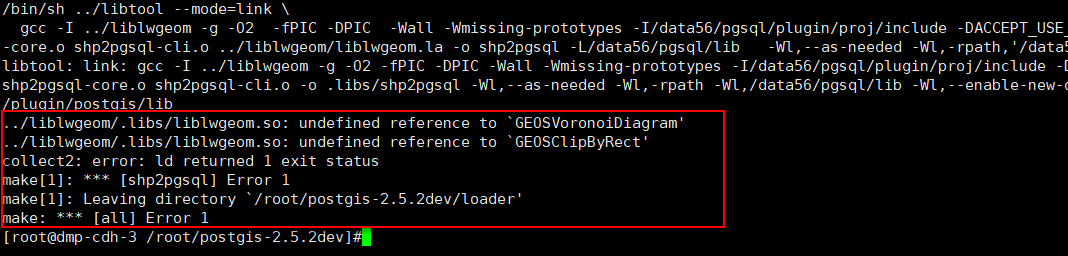
POSTGIS杂记
查询记录数
SELECT Count(*) FROM siteaddresses;多字段查询||表示连字符
SELECT siteaddres || ' ' || city || ' ' || zipcode AS str
FROM siteaddresses
LIMIT 100;
--首字母大写
SELECT
initcap(siteaddres || ', ' || city) AS address,
ts_rank_cd(ts, query) AS rank
FROM siteaddresses字符操作
操作符:
“~” Matches regular expression, case sensitive
“~*” Matches regular expression, case insensitive
SELECT array_to_string(regexp_split_to_array('the quick brown fox jumps over the lazy dog', E'\\s+'),'&');
--结果
--the&quick&brown&fox&jumps&over&the&lazy&dogregexp_split_to_array函数 用空格(正则表达式\s)分割字符串
array_to_string函数将分割后用&连接
全文检索
PostgreSQL’s full-text search includes a number of useful features:
- Matching partial words(局部词组匹配).
- Ranking results based on match quality(检索结果排序).
- Synonym dictionaries.(同义词典)
-- Add a column for the text search data
ALTER TABLE siteaddresses ADD COLUMN ts tsvector;
-- Populate text search column by joining together relevant fields
-- into a single string
UPDATE siteaddresses
SET ts = to_tsvector('simple', siteaddres || ' ' || city || ' ' || zipcode)
WHERE siteaddres IS NOT NULL;PostgreSQL allows text search queries to be logically structured so that they search out documents that include all words, any words, or a combination of those conditions using and (&) and or (|) clauses.
Find all the records with “120 CINDY CT” in them:
SELECT siteaddres, city
FROM siteaddresses
WHERE ts @@ to_tsquery('simple','120 & CINDY & CT');‘@@’操作符在这里返回boolean类型,判断tsvector 与 tsquery 是否匹配
‘simple’参数,在处理文本时采用的字典,针对不同语言有对应字典,可以实现诸如去除虚词、同义检索等,这里“simple”参数表示只是单纯的去除空格和标点符号。
通过”:*”后缀实现局部匹配
比如匹配包含120 和 以CI(i)开始的的内容
SELECT siteaddres, city
FROM siteaddresses
WHERE ts @@ to_tsquery('simple','120 & CI:*');ts_rank_cd() 函数可以计算匹配程度并给定权重,按匹配程度排序:
SELECT
siteaddres,
city,
ts_rank_cd(ts, query) AS rank
FROM siteaddresses,
to_tsquery('simple','120 & CI:*') AS query
WHERE ts @@ query
ORDER BY rank DESC
LIMIT 10;对siteaddres和city进行包装(合并显示,首字母大写)使显示更漂亮:
SELECT
initcap(siteaddres || ', ' || city) AS address,
ts_rank_cd(ts, query) AS rank
FROM siteaddresses,
to_tsquery('simple','120 & CI:*') AS query
WHERE ts @@ query
ORDER BY rank DESC;考虑到交互方便,用函数实现自动生成匹配表达式,比如输入“120 CI”自动生成上述表达式“120 & CI:*”:
-- An SQL function to wrap up the pre-processing step that takes
-- an unformated query string and converts it to a tsquery for
-- use in the full-text search
--xx ~ ' $' 表示匹配以空格结尾的字符串
CREATE OR REPLACE FUNCTION to_tsquery_partial(text)
RETURNS tsquery AS $$
SELECT to_tsquery('simple',
array_to_string(
regexp_split_to_array(
trim($1),E'\\s+'),' & ') ||
CASE WHEN $1 ~ ' $' THEN '' ELSE ':*' END)
$$ LANGUAGE 'sql';
-- Input: 100 old high
-- Output: 100 & old & high:*
SELECT to_tsquery_partial('100 old high');
--用函数替换后的表达式最终如下
--在geoserver中建立SQL表,实现输入检索文本,返回匹配内容
SELECT
initcap(a.siteaddres || ', ' || city) AS address,
a.gid AS gid,
ts_rank_cd(a.ts, query) AS rank
FROM siteaddresses AS a,
to_tsquery_partial('100 old high') AS query
WHERE ts @@ query
ORDER BY rank DESC
LIMIT 10;转载自:https://blog.csdn.net/dream15320/article/details/78364338