空间数据挖掘与空间大数据的探索与思考(三)
空间数据挖掘与空间大数据的探索与思考
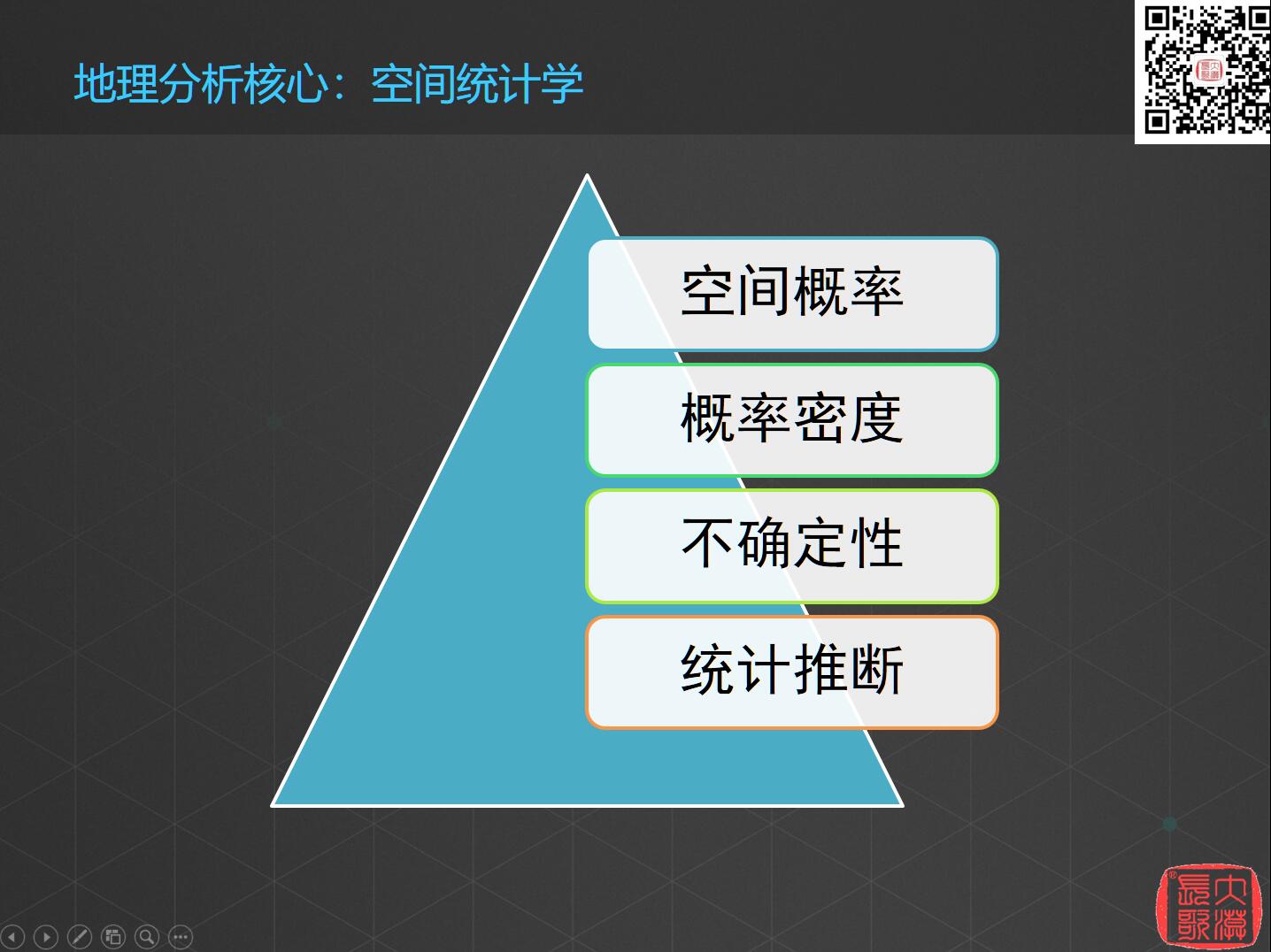
地理的分析核心是来源于所谓的空间统计学,空间统计学有四个最基本的概念:空间概率、概率密度、不确定性和统计推断。
第一个概念是空间概率,空间概率是一种符合地理学第一定律的联合概率。
说道联合概念,先得聊聊经典统计学里面的联合概率。举一个简单的例子,一个女生要找想男朋友,问我有没有啥资源可以介绍 ?我问你需要什么样的男生?她说她的要求很简单,就三个。第一个要求要长得高一点;第二个要求是长得稍微帅一点;第三个要求就是要稍微有钱一点,总之,就是三个字“高富帅”。

我说,三个条件实际上都不难,首先是高,这个很容易解决,十个人里面总有一个高个子吧,特别在北方,这个概率还能再高点。帅也不是问题,抛开个人的审美观念的不同,帅的人至少也有十分之一吧;最后有钱,现在中国现在经济这么发达,在北京挤地铁的都是百万富翁甚至千万富翁……十个人里面选一个,已经很容易了。
那么三个条件的概率都是十分之一,那是不是表示十个人里面就有一个是她的真命天子呢?所谓的联合概率,就是两件事情同时发生的概率,实际上应该是“十分之一的高乘以十分之一的帅乘以十分之一的富”。因此同时满足高、帅、富这三个条件的人只占千分之一的概率,要求一点也不低。最后再扣掉诸如已婚人士、年纪不适合的等等,那就真的不是那么好找了。

这是传统的联合概率,那么空间概率是什么呢?我们来看下图,
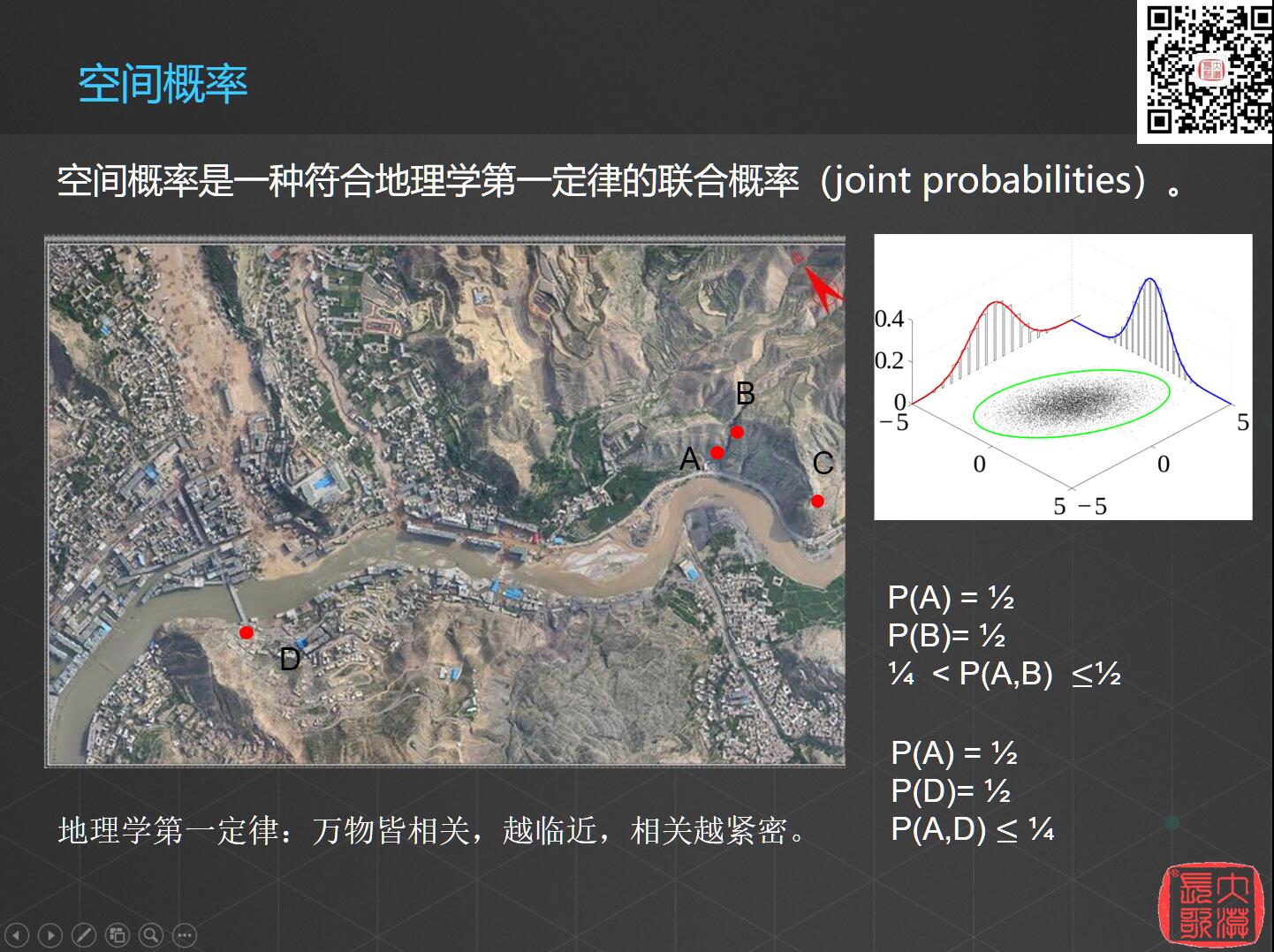
图上有4个点,如果说A点发生滑坡的概率是二分之一,B点发生滑坡的概率也是二分之一,那么A、B两点同时发生滑坡的概率是不是二分之一乘以二分之一等于四分之一呢?肯定不是,因为根据地理学第一概率,任何事物之间都是有联系的,这种联系跟距离相关,即“万物皆相关,越临近,关系越紧密”。也就是说如果A点发生滑坡,很容易就会影响到B点,所以这两点同时发生滑坡的概率应该是大于四分之一小于二分之一,这就是所谓的地理学的联合概率。那么同样的,A点、B点、C点同时发生滑坡的概率是不是也是相乘呢?肯定不是,要大于八分之一的。
第二个概念是概率密度。概率密度是指事件点处在任何一个定义区域的概率等于钟表面在这个区域上的体积,越靠近中心,定位点的密度越大。
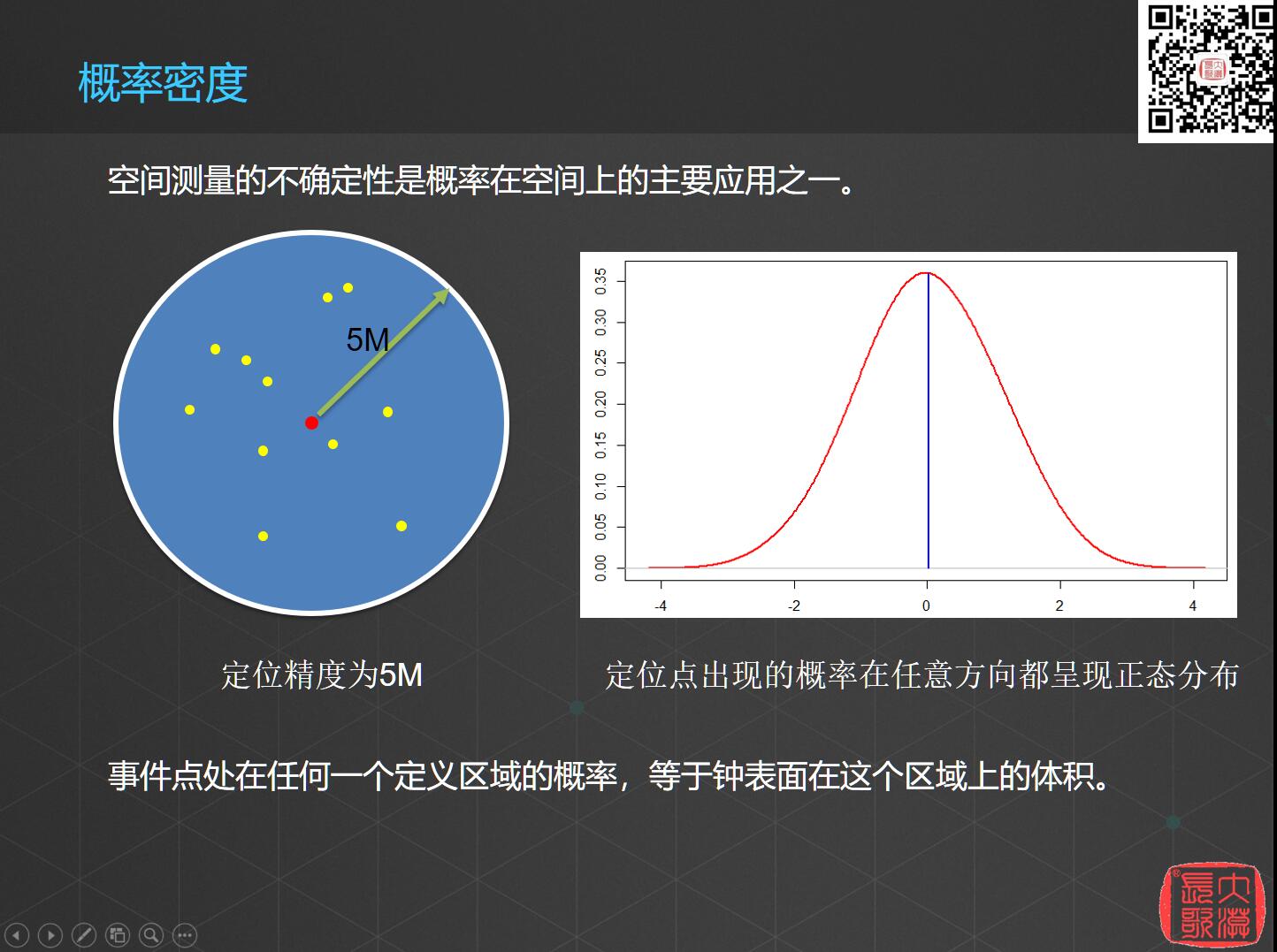
这个在空间分析上有深入的研究和应用,就比如插值,理论上样本点越多,插值的结果就越精确,离采样点越近的预测值,精度就越高,这个精度的准确率,就相当于上面给出这个概率密度。
第三个概念是不确定性。我们知道,测量是有不确定性的,但是在GIS里,不确定性是会发生传递的,每一点的不确定性都会传递到下一个点当中去。我们做测量时,每测一节,这一节产生的误差也会传递到下一节的测量中。这些不确定性,也有可能是应为观察位置不同而产生的,也正好是所谓的空间异质性的主要研究内容。

最后一个概念是统计推断,统计推断是科学研究最重要的工具之一,那么空间中的统计推断和传统的统计推断有什么不同呢?传统的统计推断只用保证随机性就可以了;但是空间统计的抽样需要保证样本之间原始的空间相关性,保证抽样不破坏数据的空间异质性。同样一批数据,抽样以后分布的疏密不同,能否保持原有的空间关系,都是需要去考虑的。以上四个概念基本上被认为是空间统计学里面的基础理论。

我们回过头来看数据,在1880年,詹姆斯·加菲尔德(美国第20任总统)说过这样一句话:“传统来说,历史学家们是以一种总体的方式来研究一个国家,他们只能给我们讲述帝王将相以及战争的历史。”小学、中学所有历史课文上面讲的都是各种战争以及伟大人物的故事,但关于人民本身——我们庞大社会中每个生命的成长、各种力量、细节等等都是历史学家们讲述不出来的。而普查把我们的观点放大到民房、家庭、工厂等任何地方,使新的历史记录成为可能。也就是从1880年开始,美国认识到数据将成为我们新的历史记录方式。中国现能获得的最早成系统的真实数据是日伪时期的地质图,2015年抗战胜利七十周年纪念时,国家地质调查局曾公布了一批资料,是从甲午中日战争开始,日本的测绘人员在中国探矿的资料。现在我们经常在做研究时发现,中国的数据太难获取了,想找十年前的数据根本找不到,而美国可以找到一百年前的数据。中国真正开始收集数据是在1995年,因为1995年中国的互联网正式接入国际互联网,那时中国的信息高速公路刚刚开通,有大量的数据往服务器上发送。现在我们的数据会越来越全,国家已经把它提到一个战略性的高度。

数据如此重要,下面我们来看看全球最大的两个数据中心。
第一个是Facebook北欧数据中心,它是民用型数据中心,这个数据中心在挪威的北极圈里,提供5亿人的数据存储。最为人称道的是它的环保,利用北极圈的冷气对服务器进行冷却,每年可以节约几百万的电费支出。

第二个叫做犹他数据中心,是军用型数据中心,其全称为“情报体系综合性国家计算机安全计划数据中心”,所属机构是NSA(美国国家安全局)。美国棱镜计划的所有数据都存放在这个数据中心,可以提供YB(YB是1024TB级的4次方,1YB,相当于1万亿个1TB的家用硬盘)。当时做了一个最简单的盘算,把这个数据中心所有硬盘全部垒起来,可以绕地球到月球一圈,它每年运营所需能源需要中国三峡发电站年发电量的六十分之一。

在这个数据中心,监控和处理全球互联网的所有数据:美国的科学家做过这样一个实验,他们在全球的任意一个节点上使用公用的账号邮箱发出任何一封匿名邮件(邮件包含一些敏感关键词,比如 “恐怖袭击”、“真主万岁”什么的),那么他们的提出的技术要求是:在24小时之内,这封信的信息出现在中情局的情报里。可见这个数据中心强大的信息收集和分析能力有多么厉害。
虾神从大学毕业之后出来干软件行业,大部分是都在做电子政务类的项目,那么国家每年花那么多钱,做了那么多项目,最后到底想要什么?
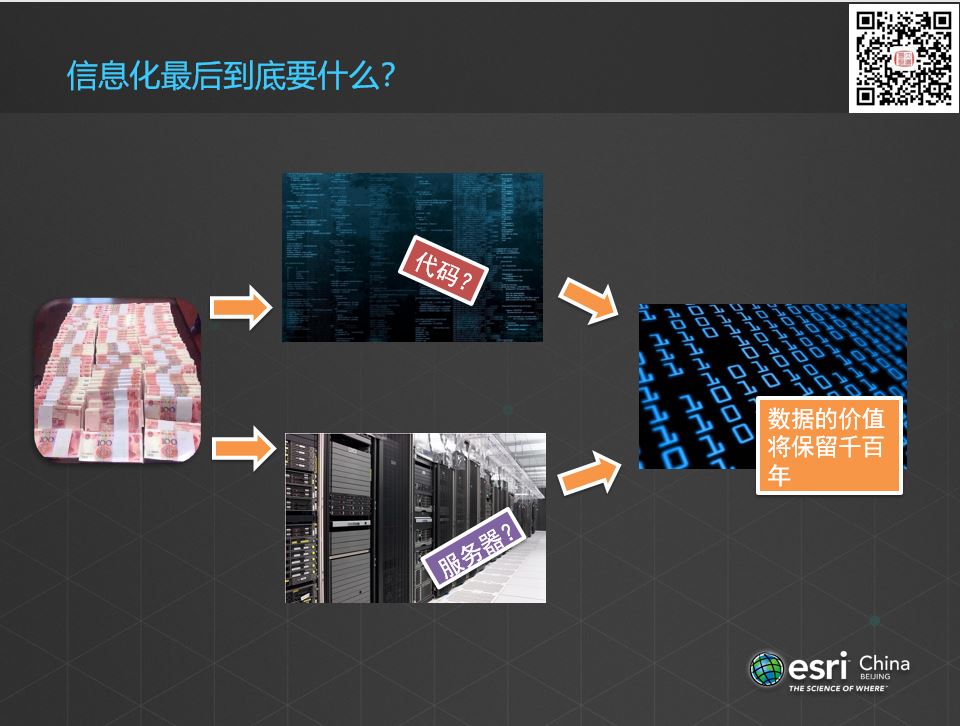
每年几十亿上百亿的信息化费用,最后需要的那些代码么?还是购买的服务器呢?十年前的软件代码还有在运行么?五年前的服务器,估计也早就淘汰了。但是有些东西留下来了,就是在系统运行过程中的数据,不管过了多久,都还着它的价值。正如加菲尔德说的,数据成为了记录历史的新的方式。
转载自:https://blog.csdn.net/allenlu2008/article/details/79600208