白话空间统计十九:热点分析(上)
白话空间统计十九:热点分析(上)
哈罗,各位好,话说虾神已经消失很久了,很多人在问是不是停止更新了?那肯定是不可能的,虾神发下宏愿,要把白话空间统计写完的。只不过这段时间遇上各种加班和一年一度的用户大会,所以就断掉了一段时间……
好吧,废话不多说,进入正题。虾神回归写的第一篇,就是大家期盼已久(虾神自己期盼已久)的热点分析了。
其实,互联网地图在最初经历了浏览查询和路径导航应用以外,在空间分析上,最先让大众所了解的,就是类似这样的热力地图了:
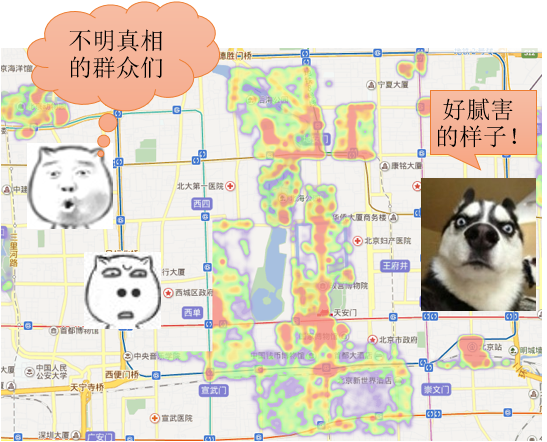
而且某度还直接挂了“热力”地图这样的高大上的名称,所以我们(不明真相的群众们)自然也就把“热点分析”当成了类似于做这种热力图的过程了。
而实际上,会被提出这样一个问题:红色的地方,自然表示热度大,表示人多,这个很容易理解,但是有些被标明是“冷点”的地方,真的是表示人少么?
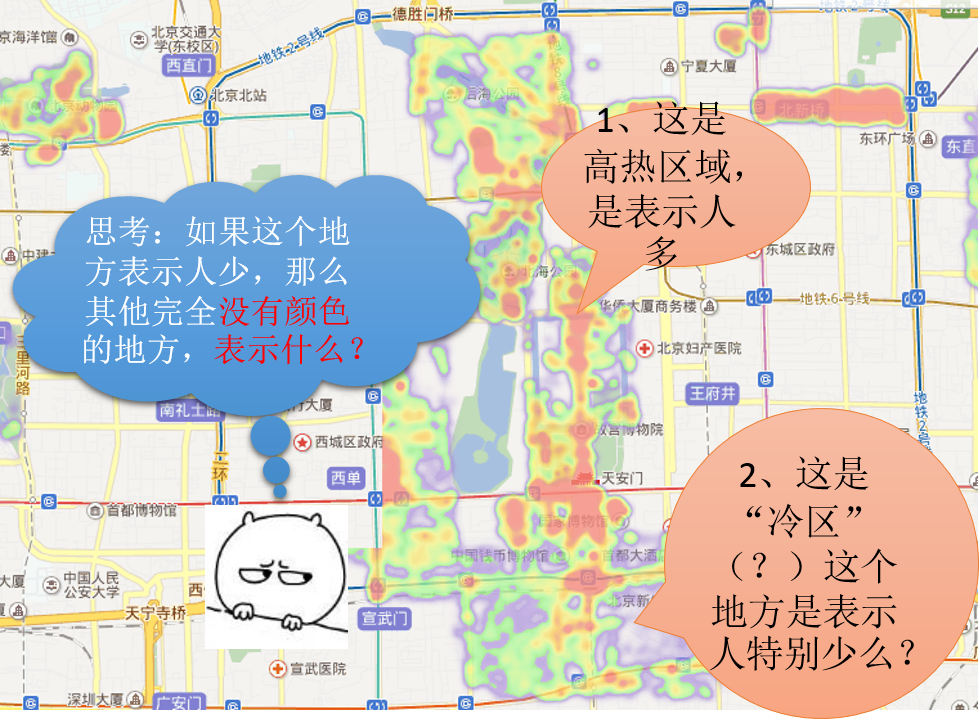
回答自然不是,正如上面思考的内容,如果蓝色的地方,是冷点,是人少的话,那么没有颜色的地方呢?
所以,得出如下这一结论:

那么,热力图,在空间分析里面,叫做什么呢?实际上,热力图,在空间分析里面,他的专业名词,叫做“密度分析”。而且类似百度这种热力图,仅仅是密度分析里面的“点密度”,也就是代表一个个人的点,单纯的按照数据的多少,来进行聚集,而不去考虑权重、空间关系等内容。
不过,群众喜闻乐见的东西,才是好东西,我对于百度能够将这种空间分析的思路推向大众,那是万分的尊崇的,这才是一个科普工作者应该做的事情。
前面花这么大篇幅讲解,主要就是更正一个名词,热力图,不等于热点分析,所以,我这篇博客写完之后,很多同学肯定会严重的质疑:为什么虾神你的热点分析,做出来的东西和百度的热力图完全不一样捏?所以现在我先进行正名:热点分析不等于热力图、热点分析不等于热力图、热点分析不等于热力图(重要的事情说三遍)。
当然,百度这种热力图怎么做,以后我讲到密度分析的时候,会专门讲,老规矩——挖坑待填……
热点分析的算法叫做Getis-OrdGi* 统计(称为 G-i-星号)。看着是不是很眼熟啊!恭喜你,答对了,我们前面讲过一个“高/低值聚类”,叫做Getis-Ord
GeneralG,是由美国乔治敦大学麦克多诺商学院(McDonough School of Business)的J. Keith Ord和圣地亚哥州立大学地理系的Arthur Getis两人提出的,而这个Gi*算法,是这个高低值聚类算法的进阶版。
关于高/低值聚的Getis-Ord GeneralG算法,不记得了的同学请回头去看白话空间统计之十四……这里就不多说了。
那么热点分析是用来干嘛的呢?
我们知道,空间统计里面,最重要的两个值就是P值和Z得分,所以他们首先肯定是计算P值和Z得分的了(不记得P值和Z得分是干嘛的,请看以前的文章)。
通过得到的 z 得分和 p 值,我们可以知道高值或低值要素在空间上发生聚类的位置。但是这个工具的工作方式有些特殊:它查看邻近要素环境中的每一个要素。高值要素往往容易引起注意,但可能不是具有显著统计学意义的热点。要成为具有显著统计需意义的热点,要素应具有高值,且被其他同样具有高值的要素所包围。
听到这句话,是不是又有了似曾相识的感觉了?不错,这个解释不就是Anselin Local Moran’s算法要解决的问题么?高的和高的蹲一起,低的和低的蹲一起,如下图:
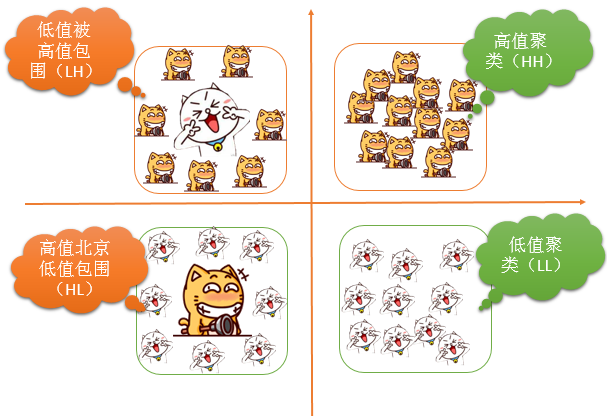
但是,Anselin LocalMoran’s算法,很容易出现下面这样的问题:
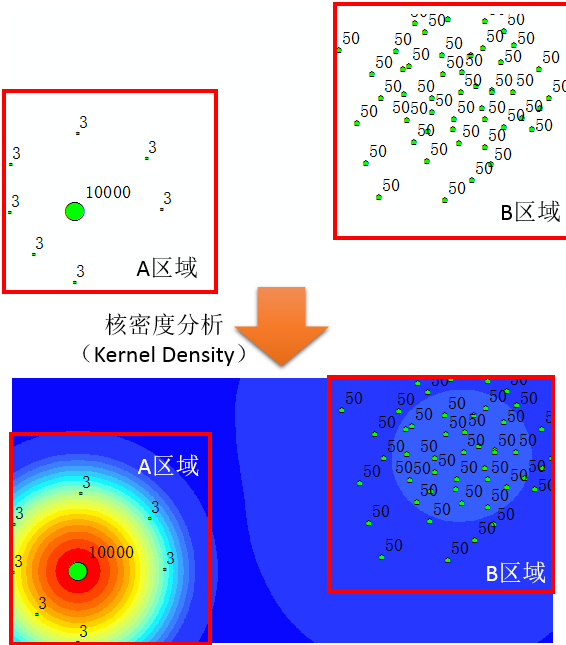
我们可以看见,A区域有一个点,值高达10000,其他的点的值都是3,是典型的HL(高值被低值环绕),而B区域都是50,属于标准的低值聚类,但是通过核密度(也就是所谓的热力图)计算,HL区域极度的高热……这就是前面说的,高值要素往往让人特别的关注,但是实际上是否是具有统计学意义上的热点呢?还是未必的。
所以,无论是在心理学里面,还是在实际分析的过程中,都很容易出现这种问题的:

所以,从上面两个例子,我们可以看到,在统计学的热点分析和热力图这种密度分析,是完全不同的概念。那么这个热点分析到底是什么东西呢?欲知后事,请听下回分解。
转载自:https://blog.csdn.net/allenlu2008/article/details/49231029