白话空间统计十七:聚类和异常值分析(Anselin Local Moran’s I)(下)
前文再续,书接上一回。
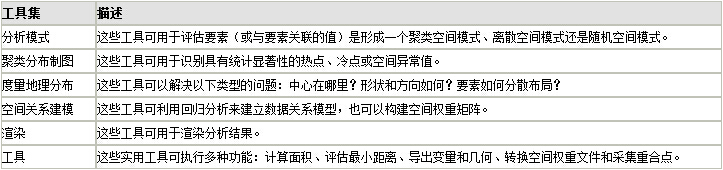
AnselinLocal Moran’s I作为细粒度的空间统计工具神器,在ArcGIS里面自然也是提供了相应的工具的,
这个工具就直接叫做“聚类和异常值分析”(Cluster and Outlie Analysis(Anselin Local Morans I))。
在后面的括号里面保留了以老帅哥Anselin教授命名的算法的名称,不管中英文都有,说明了大家和虾神一
样,对于研究算法的大神们都有顶礼膜拜的情节。
这一章主要讲讲AnselinLocal Moran’s I算法的原理和工具使用方法。
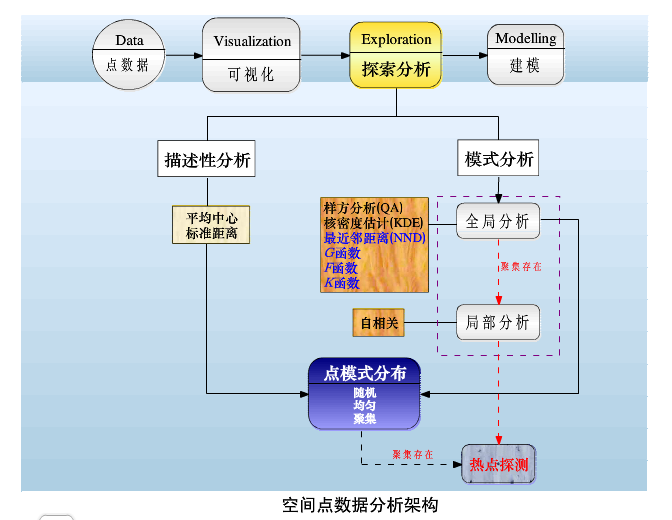
其实一直都忘记了补一章,关于空间数据探索的基础,实际上在讲空间概率标准化的时候就应该写的
,可有些时候因为想对照着ArcGIS的空间统计模块来写(关键没有其他的参考书,只能参考这个了,
话说Esri这个帮助文档,实在是空间统计学的入门必看经典啊!),结果不小心就把这个内容给漏掉
了……真是尽信书不如无书啊!
这个空间数据探索的基础,就是的空间权重矩阵。如下所示:

好吧……权重矩阵,我们看看看这个空间权重矩阵到底是个啥东东:
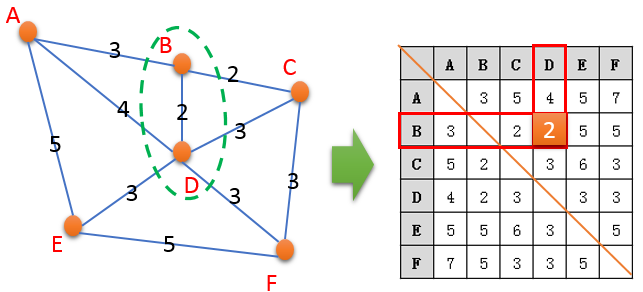
左边这个东西,叫做无向图,由边那个,就是所谓的距离矩阵了。因为我们以前说过,在
空间分析里面,需要进行空间关系的概念化,所以也通常称为空间权重矩阵。
当然这个权重矩阵为了简单明了,所以用的直接就是用最短距离作了矩阵里面的元素,比
如B和C的距离,直接通过矩阵可以查询到WBC
= 2
。
但是实际上情况可能会更复杂,比如我们以前说过,空间关系概念化一共有7种概念,每
种概念都能够变化成相应的权重矩阵。比如最简单的,判断是否相邻的空间权重矩阵,
可能就只有两个值,如下:
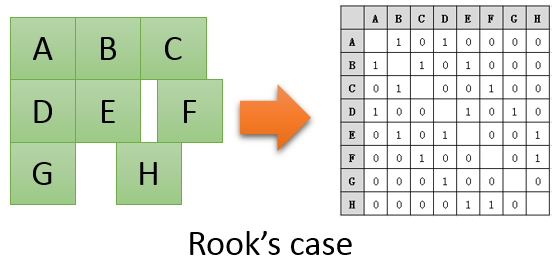
通过这个空间权重矩阵,很容易的看出各个面要素之间的关系,比如D要素,与A\E\G三个
要素有相邻关系。
关于啥是Rook’s case的不记得请去看空间统计之五:空间关系的概念化这篇文章,我这里就
不复习了。
这个权重矩阵与后面我们要进行的计算,是非常相关的。当然,因为现在的各种工具里面,
在计算Anselin Local Moran’s I的时候,都会依照你给定的空间关系概念化(也就是所谓的距
离计算方式),来生成这个权重矩阵,但是如果不预先生成,使用不同的软件去计算的话
,都会出现不同的结果。但是如果你用了同样的权重矩阵的话,计算出来的结果就是一样的。
如果说,全局莫兰指数是按照所有的数据配合空间权重矩阵计算出来的一个综合的数值,
那么局部莫兰指数的计算方法与全局莫兰指数大致是一样,所不同的是没有了权重矩阵
和数据值平均数的聚合计算过程。所以在每一个要素上面都会计算出一个属于自己的
莫兰指数。如下:
当然,做为空间相关性的算法,算完之后P值Z得分肯定是跑不掉的,正因为有了莫兰指数
和Z值的组合,才会有HH,LL,HL和LH四种可能。他们的具体在四个象限的分布如下:
下面的部分,请参考修正部分:
郑重道歉:聚类和异常值分析(Anselin Local Moran’s I)修正篇
转载自:https://blog.csdn.net/allenlu2008/article/details/48556421