白话空间统计二十:相似性搜索(二)
首先打个广告,在这个开心的开心,伤心的伤心的节日里面,请大家关爱一下虾神这样的单身狗,没有买卖,就没有杀害……
当然,其他时候,能关爱的也尽量关爱一下……
好了,文归正传。
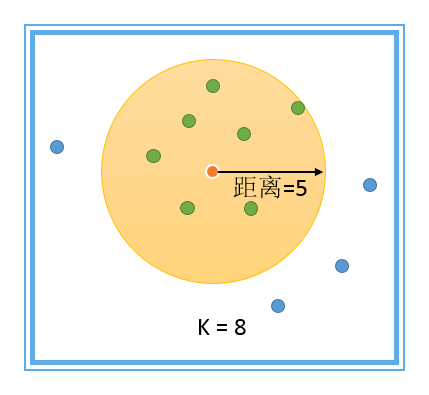
相似性搜索,说起来似乎很高大上,实际在狭义上,还是基于数值的查询方式,只不过从yes or on的二元方式,扩展到了范围域的包含性查询而已。如下:
一般来说,相似性搜索,有六种模式:
1、相似性范围查询:寻找一点范围内的数据,以半径r为范围域,这种也是最常用的一种相识查询,GIS查询功能里面的缓冲、包含等查询方式,都是基于这个原理的。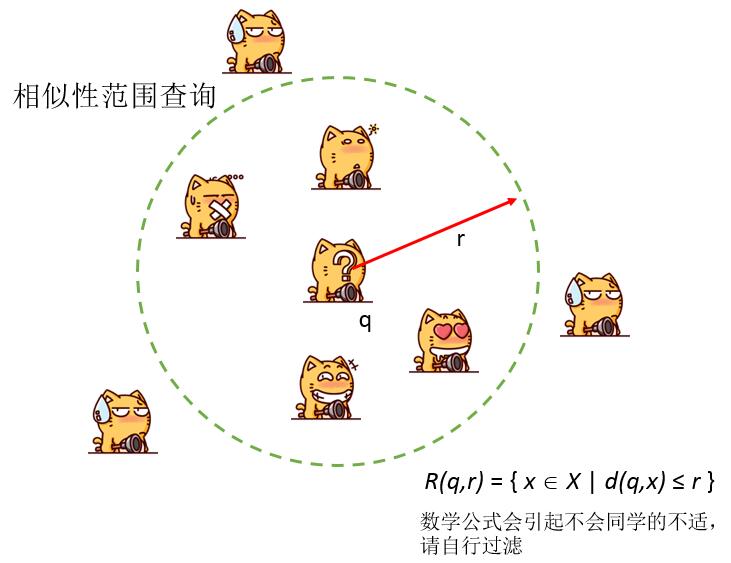
2、邻域查询: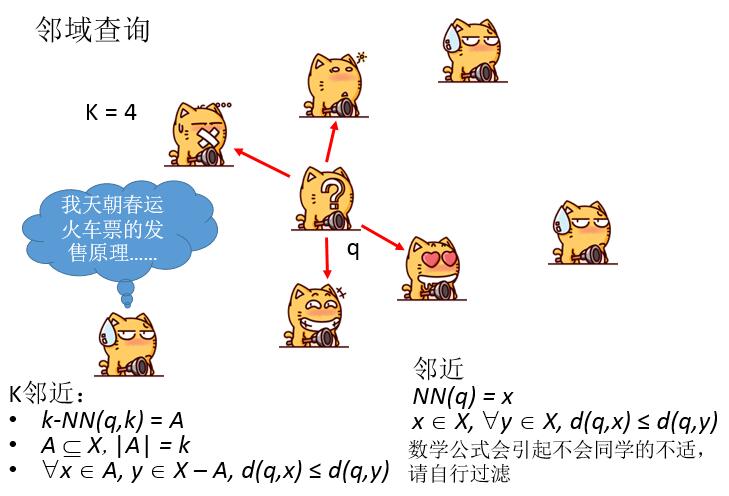
3、反向邻域查询:所谓的反向,就是把源和目标反过来,如果以我为中心去查询旁边的内容称之为正向的话,周边有很多个点,要查询离所有内容最近的点,就是反向查询了。我们之前在白话空间统计的七、八两章,专门讲的中心要素和中位数,都是这种查询。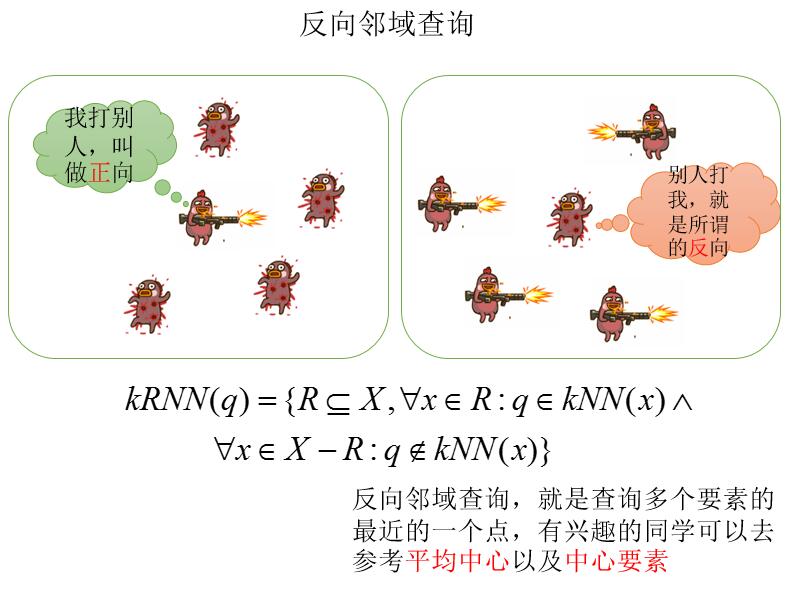
4、相似查询:这里的相似查询,指的就是两组数据之间,如果差异小于等于固定的范围域μ,那么就认为他们是相似要素。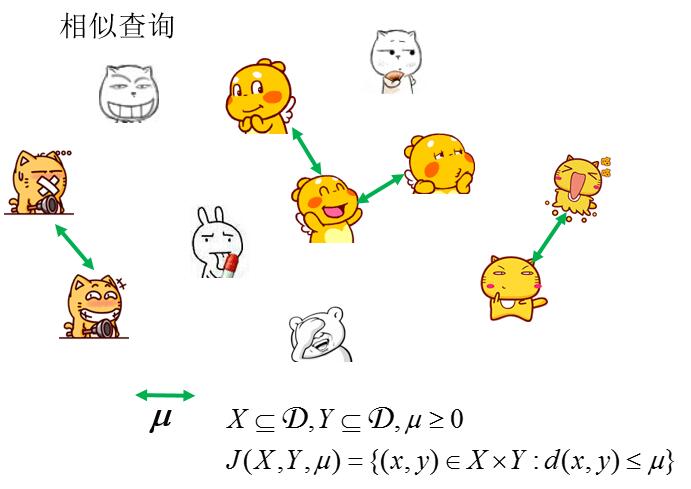
5、复合型查询:所谓的复合,就是把两个或者多个条件都加起来,然后把结果取交集,如下:
6、复杂查询
最后一个复杂查询,就近似于人工智能的分析过程了,最简单的实现算法称之为A0算法,即:穷举遍历,,然后通过各种数据匹配的方法(如模糊代数、加权计算等)、生成,进行判定最优集合或者排名,进行匹配的方法。
具体的算法的描述,如下图:(看不懂的,挖坑待填):
最在这个快(bei)乐(shang)节日,虾神以亲身经历提醒一句:单身狗不能吃巧克力……狗吃巧克力会挂的哦……单身狗也是狗……

转载自:https://blog.csdn.net/allenlu2008/article/details/50662966