
PostgreSQL分组(GROUP BY子句)
PostgreSQL分组(GROUP BY子句)
PostgreSQL GROUP BY子句用于将具有相同数据的表中的这些行分组在一起。 它与SELECT语句一起使用。
GROUP BY子句通过多个记录收集数据,并将结果分组到一个或多个列。 它也用于减少输出中的冗余。
语法:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
注意:在
GROUP BY多个列的情况下,您使用的任何列进行分组时,要确保这些列应在列表中可用。
看看下面的例子:
我们来看一下表“EMPLOYEES”,具有以下数据。

执行以下查询:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
查询得到如下结果 –

如何减少冗余数据:
再来看看下面这个例子:
我们在“EMPLOYEES”表中插入一些重复的记录。添加以下数据:
INSERT INTO EMPLOYEES VALUES (6, '李洋', 24, '深圳市福田区中山路', 135000);
INSERT INTO EMPLOYEES VALUES (7, 'Manisha', 19, 'Noida', 125000);
INSERT INTO EMPLOYEES VALUES (8, 'Larry', 45, 'Texas', 165000);
现在有以下数据,有一些数据是重复的 –
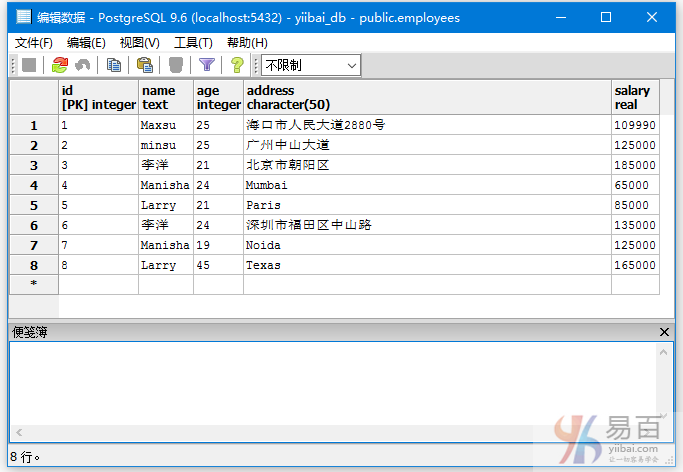
执行以下查询以消除冗余:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
上面的SQL语句是按名字(NAME)执行分组统计每个名字的薪水总额,如:两个名字叫作李洋的薪水总额是:320000等等,得到结果如下 –

在上面的例子中,当我们使用GROUP BY NAME时,可以看到重复的名字数据记录被合并。 它指定GROUP BY减少冗余。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:”教程” 选择相关教程阅读


I’m really impressed along with your writing
abilities as neatly as with the format for your blog.
Is that this a paid subject matter or did you modify it your self?
Anyway stay up the excellent high quality writing, it is
rare to look a great weblog like this one these days. Blaze AI!