
WFST
目录
主要参考资料 speech recognition with weighted finate-state tra
WFST简单笔记(一)
WFST(weighted finaite-state transducer)用于大规模的语音识别,包括HMM模型,词典,n-gram语言模型。
WFST状态转换用输入和输出符号标记。 因此,transducer将路径编码从输入符号序列或字符串到输出字符串的映射。WFST除了输入和输出符号之外还对转换进行加权。 权重可以编码概率,持续时间,惩罚或沿路径积累的任何其他数量,以计算将输入字符串映射到输出字符串的总体权重。 因此,加权传感器是表示在语音处理中流行的概率有限状态模型的自然选择。
总述
1.WFSA
WFSA(weighted finitestate acceptors),可以识别从初始状态到结束状态的一整条路径
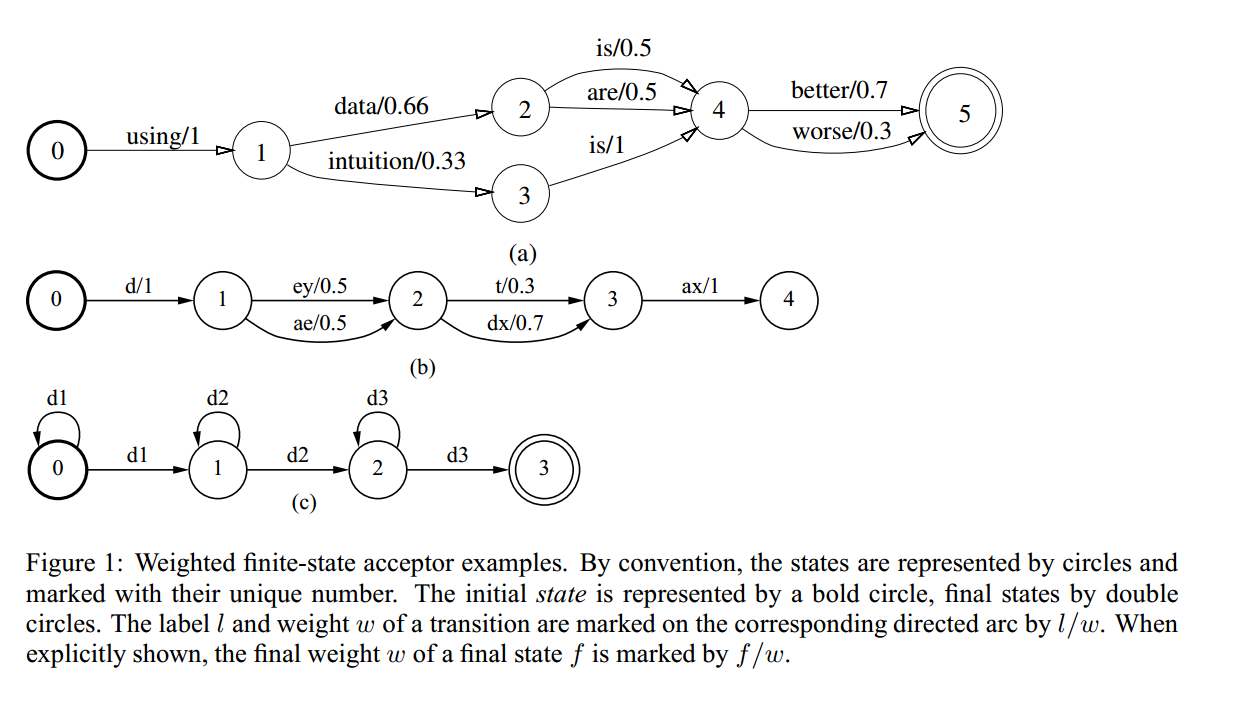
图1a是简单的有限状态的语言模型,每条路径上都有相应的词串和转移概率,图1b则是一个完整的词,图1c显示了一个音素的HMM模型
2.WFST
WFST和WFSA十分相似,区别在于每个转移上都有输入标签,输出标签和相应的权重
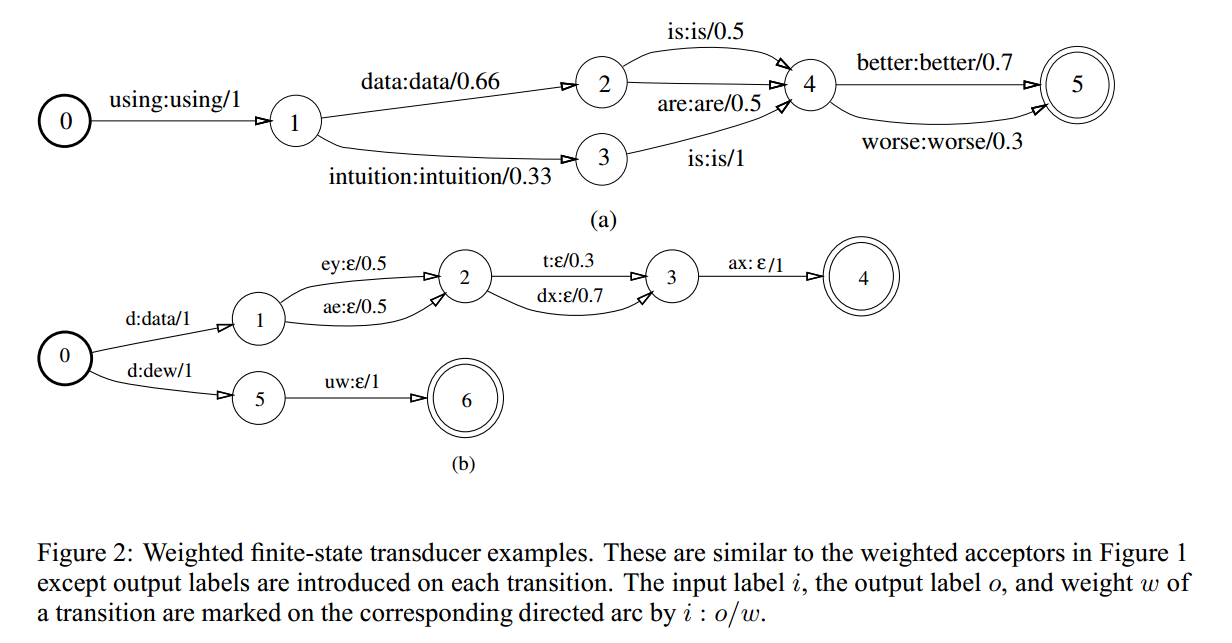
图2a和1a表示的语言模型是相同的,2b表示一个简单的发音词典,例如data和drew,从音素映射到单词。如上图显示,每条路径对应的发音是第一个输入音素对应的输出,之后的音素没有输出,符号€表示空,因此WFST可以把两个级别的表示连接起来,比如说单词和音素,或者HMM和单音素。此外WFST定义了一个二元关系,第一个序列是输入标签,第二个序列是输出标签。相同的输入会有不同的输出路径,因此每一个序列对用权重来表示。
3.Composition
Composition是transducer的关键操作,用来连接不同级别的表示。假设有两个转换器T1,T2,T1把u映射为v,T2把v映射到w,所以compositionT=T1 ο T2,如果权重表示的是概率,则操作为乘,若权重表示的是对数概率,操作就是加。
这个加权组合算法生成了一个状态对,T的状态是由T1和T2的状态生成的。(1)T的初始状态是(q1,q2),分别对应T1,T2的初始状态;(2)T的结束状态是(r1,r2),分别对应T1,T2的结束状态,(3)从q到r的转移变换用t表示(t1,t2),并且t1的输出标签与t2的输入标签相匹配。转移变换t从t1得到输入标签,从t2得到输出标签,权重由t1,t2权重组合生成,下图中是相加。
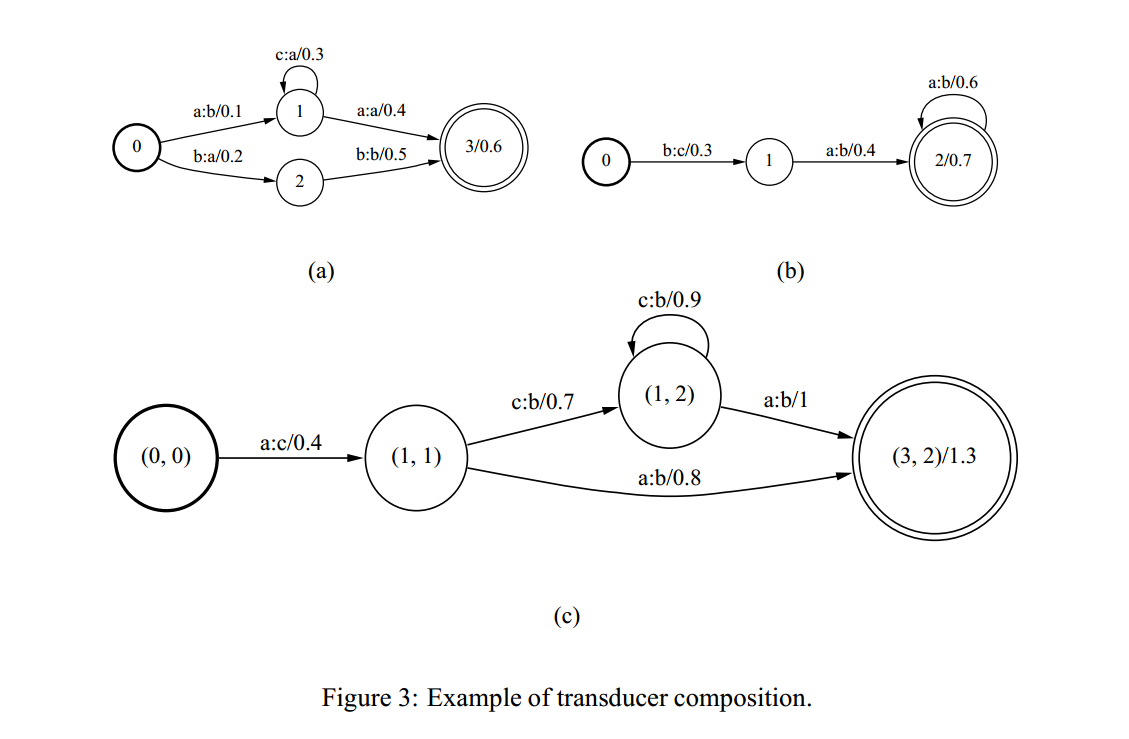
4.determinization
在确定性自动机中,给定一个输入标签,每个状态只有一个转换状态,图4给出两个不同的weighted accceptor
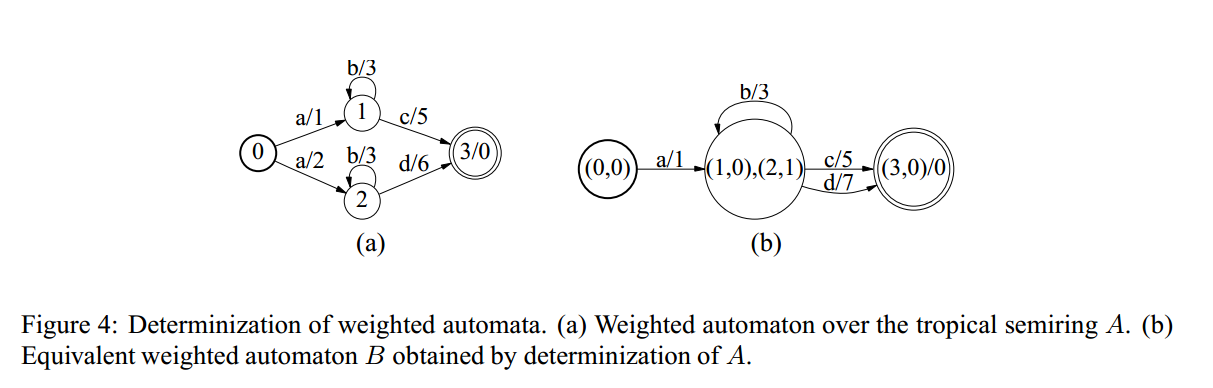
不是每一个加权自动机都可以使用确定性算法,但是在大多数语音处理中,都可以确定,或者是通过一定变换方法来确定,值得注意的是任何加权非循环自动机都可以被确定。
为了消除冗余路径,需要计算具有相同标签的所有路径的组合权重。 当每个路径表示相应概率(尤其权重给出)的不相交事件时,表示该组路径的组合权重将是路径的权重之和。定义两种操作:使用⊗来组合路径上的权重,以及用于component,⊕来组合相同标记的路径。经常使用的 (⊕, ⊗)选择包括 (max, +),
(+, ∗),(min, +)以及 (− log(e−x + e−y), +)
图4a中,a-b有两条路径min{1+3,2+3}=4,因此图b中从a-b也是4。在用于确定未加权自动机的经典子集构造中,通过给定输入从初始状态可达到的所有状态都被放置在同一子集中。 在加权情况下,具有相同输入标签的转换可以具有不同的权重,但是仅需要这些权重的最小值,但是我们必须保留剩余权重。 因此,加权确定中的子集包含原始自动机的状态q和剩余权重w,(q,w)。
初始子集是(i,0),i是原始自动机的初始状态
未完,determinization不是很懂,继续学习!
转载自:https://blog.csdn.net/sky1170447398/article/details/70159865


